redo log负责记录物理数据页,所以无论执行多少次都是幂等的;而binlog是记录逻辑数据,执行多次就可能重复数据。
数据结构是一个环形数组,innodb将未写入磁盘的页叫做脏页,redo log的作用就是记录脏页的数据。
在宕机恢复时,一个事务是否持久化是根据redo log刷盘情况决定的。如果一个事务的redo log已经全部刷入磁盘,那么这个事务是有效的,反之需要根据undo log回滚。
redo log在硬盘中是分成多块来存储的,以ib_logfile[number]命名。
执行SHOW GLOBAL VARIABLES LIKE "innodb_log%";,
+-----------------------------+-----------+
| Variable_name | Value |
+-----------------------------+-----------+
| innodb_log_buffer_size | 67108864 |
| innodb_log_checksums | ON |
| innodb_log_compressed_pages | ON |
| innodb_log_file_size | 536870912 |
| innodb_log_files_in_group | 4 |
| innodb_log_group_home_dir | ./ |
| innodb_log_write_ahead_size | 8192 |
+-----------------------------+-----------+
innodb_log_files_in_group指定了redo log文件被分为几部分,每一部分的文件大小都是一样的,当写入ib_logfile3后,又继续写入ib_logfile0,如此循环。
这是在磁盘里的文件,
[root@dev_test63 mysql3306]# ll ib*
-rw-r----- 1 mysql mysql 683671552 5月 20 01:25 ibdata1
-rw-r----- 1 mysql mysql 536870912 5月 20 01:24 ib_logfile0
-rw-r----- 1 mysql mysql 536870912 5月 19 11:10 ib_logfile1
-rw-r----- 1 mysql mysql 536870912 5月 20 01:24 ib_logfile2
-rw-r----- 1 mysql mysql 536870912 5月 20 01:25 ib_logfile3
-rw-r----- 1 mysql mysql 79691776 5月 20 01:01 ibtmp1
- ibtmp1是临时表空间,ibdata1是共享表空间。
为什么要有redo log:
- redo log是顺序写入的,而数据页落盘是随机存储。
- 延迟刷脏页可以起到合并多次修改的作用,mysql的最小存储单位是页,一个页有多行,如果每次修改一行就要更新整个页,并不是那么能接收。
有了redo log之后,对于一行数据,首先更新buffer pool(在这之前还有undo log),然后再写入log buffer。
组织结构
由于redo记录的是物理变更,比如在“第100表空间第100页偏移量1024写入4个字节balabala”,而不是描述第几行改成什么样,一行记录变更涉及的物理页可能有很多,所以可能产生一条redo log,也有可能是多条redo log,这个和undo log不同。
redo log
这是一条redo log的通用结构

- type:redo log的类型,可能是基础类型,也可能是复杂类型
- Space ID:表空间id
- page number:页号
- data:redo log内容
具体type的类型有很多,参考底部链接,其中包括undo log对应的redo logMLOG_UNDO_INSERT。一个操作产生的redo log可能是一个,也可能是一组redo log。
生成undo log的时候会写redo log。当数据恢复的时候,可以根据undo log恢复还没刷盘的undo log。
log block
组织redo log的是log block,一个log block是存储redo log的基本单位,和页有点类似。
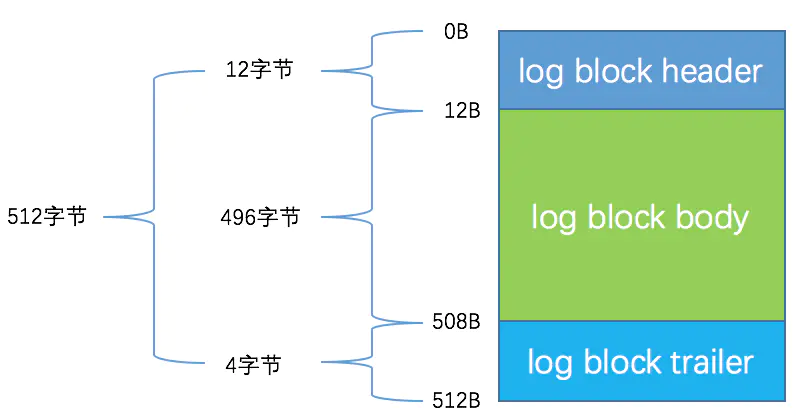
- log block header:存放block信息
- log block body:存放多条redo log
- log block trailer:存放block的校验值,用于正确性校验
log buffer和log file都是以log block为基本操作单位,redo log在log block里顺序写入。
mtr
Mini-Transaction,即mtr,
前面说到一个操作可能产生一组redo log,那么这组redo log是需要保证事务性的,innodb使用mtr这种比transaction更小粒度的事务,来保证一组redo的事务性。
mtr开启后,会定位到要修改的page的位置,对索引加锁;之后执行一系列写操作,期间产生的redo log会暂存在mtr对象中;mtr提交时,需要把暂存的redo log组放入log buffer中,然后把修改的脏页放入flush list,之后释放page的锁。
刷盘策略
这里有几个概念
- buffer pool:指在内存中的数据页,innodb需要把物流数据页读到内存中进行修改。
- log buffer:指redo log的buffer,属于进程。
- redo log file:指内存中的redo log文件,属于操作系统,待fsync到磁盘中。
redo log刷盘时机如下:
- 有事务提交时,根据事务提交时的刷盘策略决定是否刷盘
innodb_flush_log_at_timeout默认值为1,也就是1s内如果没发生刷盘,需要进行刷盘- 当log buffer中已经使用的内存超过一半时
- 当到达checkpoint时
事务提交时的刷盘策略
innodb_flush_log_at_trx_commit指定了redo log的事务提交刷盘策略,分别三个值
0:每次提交事务,不会将log buffer写入redo log file,而是由master thread每秒将log buffer写入redo log file,并调用fsync落盘
1:每次提交事务,将log buffer写入redo log file,同时调用fsync落盘,是最严格也是性能最差的策略
2: 每次提交事务,将log buffer写入redo log file,每秒调用fsync落盘
0和2看起来有点相似。区别在于,前者没有将log buffer同步写入redo log file,要知道redo log file是文件,所以0没同步写入文件,性能会比2高,但mysql崩溃时,会丢失日志;而2同步写入文件,已经将日志提交到操作系统了,只有操作系统宕机了才会丢失日志。
我们线上数据库innodb_flush_log_at_trx_commit的值是1,有一次同事清理数据时做了个全表更新,redo log疯狂刷盘,从而导致数据库缓慢,于是运维关闭了双1(innodb_flush_log_at_trx_commit和sync_binlog),暂停了清理脚本,才得以恢复。
LSN
Log sequence number是一个8字节的不断增长的数字,表示日志编号,起到一个类似版本的作用,很多地方都有这个LSN,最终需要这n个地方的LSN达到一致。
通过LSN可以获得:
- 数据页的版本信息。
- 写入的日志总量,通过LSN开始号码和结束号码可以计算出写入的日志量。
- 可知道检查点的位置。
执行SHOW ENGINE INNODB STATUS;可以看到和LSN有关的信息:
---
LOG
---
Log sequence number 1509428892
Log flushed up to 1509428892
Pages flushed up to 1509300590
Last checkpoint at 1509300581
0 pending log flushes, 0 pending chkp writes
3554874 log i/o's done, 0.00 log i/o's/second
Log sequence number是redo log buffer的LSN log flushed up to是刷到redo log file在硬盘中的LSN; pages flushed up to是已经刷到磁盘数据页上的LSN last checkpoint at是上一次检查点所在位置的LSN
可以看到LSN不是完全一致,测试环境db是空闲的,Log sequence number和log flushed up to是相同的,pages flushed up to落后,这是因为脏页很少的话可以暂时不刷到磁盘。
一般来说,log sequence number > log flushed up to 和 pages flushed up to > last checkpoint at
可能会出现数据页刷盘快于redo log刷盘的情况,这时checkpoint是有机制保护数据慢于日志,所以会暂停数据页刷盘,等待日志刷盘进度超过数据刷盘。
由于记录物理数据页,如果在一个事务里把a更新成b,又把b更新为a,会不会保存到redo log里的?
试验过后,执行SHOW ENGINE INNODB STATUS\G,可以看到Log sequence number有增加;
checkpoint
由于redo log相当于给数据页做了个备份,所以事务提交时并不一定要把数据页落盘。但是:1:buffer pool是有限的,2:redo log buffer是有限的。 所以需要一个时机,将buffer pool里的数据落盘,同时清除redo log buffer里已经落盘的数据页,这个时机就是checkpoint。数据库重启后的恢复,只需要从checkpoint lsn算起,checkpoint lsn之前的数据都是认为已经持久化的。
checkpoint的目的很简单,即把数据页落盘,但是什么时候、刷多少页到磁盘、从哪里取脏页都有些不同。
checkpoint_lsn是指checkpoint发生刷盘之后,记录此次checkpoint的lsn到redo log file的第一个文件头可以理解为管理数据页缓冲的数据结构,需要保证 FLUSH列表:LRU的 有两种Checkpoint,分别为:Sharp Checkpoint、Fuzzy Checkpoint。
Sharp Checkpoint是全部刷盘,发生在切换redo log文件或者数据库关闭的时候,需要把buffer pool的数据页全刷盘。
MySQL停止时是否将脏数据和脏日志刷入磁盘,由变量
innodb_fast_shutdown={ 0|1|2 }控制,默认值为1,即停止时忽略所有flush操作,在下次启动的时候再flush,实现fast shutdown。
Fuzzy Checkpoint是部分刷盘,分为四种。
master thread checkpoint
由master线程控制,每1秒,每10秒刷入一定比例的脏页到磁盘,异步。
flush_lru_list checkpoint
从MySQL5.6开始可通过innodb_page_cleaners变量指定专门负责脏页刷盘的page cleaner线程的个数,该线程的目的是为了保证lru_list表有可用的空闲页。
async/sync flush checkpoint:
同步刷盘/异步刷盘。例如还有非常多的脏页没刷到磁盘(非常多是多少,有比例控制),这时候会选择同步刷到磁盘,但这很少出现;如果脏页不是很多,可以选择异步刷到磁盘,如果脏页很少,可以暂时不刷脏页到磁盘。
这里有四个配置
innodb_log_files_in_group=4
innodb_log_file_size=4G
总文件大小: 17179869184
log_sys->max_modified_age_async = 12175607164 (71%)
log_sys->max_modified_age_sync = 13045293390 (76%)
log_sys->max_checkpoint_age_async = 13480136503 (78%)
log_sys->max_checkpoint_age = 13914979615 (81%)
设,checkpoint_age = log_lsn - last_checkpoint_lsn,max_modified_age = log_lsn - 脏页最小lsn
当max_modified_age > max_modified_age_asyncs,需要flush_list取出脏页,异步刷盘 当max_modified_age > max_modified_age_sync,需要flush_list取出脏页,同步刷盘
当checkpoint_age > max_checkpoint_age_async,可以无需等待checkpoint完成 当checkpoint_age > max_checkpoint_age,需要同步等待checkpoint完成
dirty page too much checkpoint
脏页太多时强制触发检查点,目的是为了保证缓存有足够的空闲空间。脏页比例由变量 innodb_max_dirty_pages_pct 控制,MySQL 5.6默认的值为75,即当脏页占缓冲池的75%后,就强制刷一部分脏页到磁盘。
关于上面提到的列表:
lru_list:是一个使用了最近最少使用算法的列表,可以理解为管理数据页缓冲的数据结构。 flush_list:lru的的脏页会放进这个列表,但是不会从lru移除,所以脏页会存在两个地方。flush_list里的脏页会根据lsn最为排序依据,保证lsn小的先落盘。 free_list:free_list如果没有空闲页可以分配,就会从lru_list批量淘汰数据页以供使用。
redo log太大和太小
可以看到,async/sync flush checkpoint这种类型的checkpoint其实是和log_file的大小有关的。如果log_file小了,会使checkpoint变多,影响innodb性能;如果log_file大了,两次checkpoint跨度大,在恢复的时候可能就会等待太久(挂了跑路吧😄)。
具体多大应该结合实际测试。
两阶段提交 崩溃恢复
另外讲。