Innodb学会是不可能学会的,这辈子都学不会的。
innodb是一个日志先行(Write-ahead logging)的存储引擎,这也是大部分关系型数据库的特点。而像redis这样的nosql就是数据为先,再进行落盘。
undo log和redo log和binlog,这三个log是mysql及innodb的关键。这三种日志都会刷盘,其中:
- undo log: 事务原子性和多版本控制MVCC(事务隔离)
- redo log: 事务持久性,宕机恢复
- binlog: 宕机恢复,主从同步
可以看出三个日志在对应功能上需要相互协作。undo log和redo log是事务日志;redo log要等binlog写入成功才能commit;undo Log保证事务的原子性,redo log保证事务的持久性。
网上大多都是讲undo log能做什么,但没几篇讲清楚undo log组织结构。innodb最小存储粒度是页page,而页就分为FIL_PAGE_INDEX索引页(索引即数据)和FIL_PAGE_UNDO_LOGundo页。
部分概念是关于MVCC的,需要配合[Mysql]Innodb的快照读实现食用,本文不做讨论。
undo log就是个历史版本,落盘后不和redo log存在一起。
表空间
InnoDB存储引擎提供二种数据库表的存储方式
- 系统表空间:所有数据上放在一起,物理文件可以拆成多个文件。
- 独占表空间:每个表有自己的物理文件,性能更好。
关于更多不在讨论范围。
结构层次
Rollback Segment(rseg)称为回滚段。Mysql5.6之前undo默认记录到系统表空间(ibdata),如果开启了 innodb_file_per_table ,将放在每个表的.ibd文件中。5.6之后还可以创建独立的undo表空间,8之后更是默认打开独立undo表空间,最低数量为2,这样才能保证至少一个undo表空间进行truncate,一个undo表空间继续使用。独立undo表空间的文件格式是undo001,undo002……
每个rollback Segment中默认有1024个undo log segment,mysql5.5后1个undo表空间支持128个rollback Segment。0号rollback Segment默认在系统表空间ibdata中,1-32rollback Segment在临时表空间,33~128在独立undo表空间中(没有打开则在系统表空间ibdata中,这样系统表空间会太大),所以1个表空间最多支持96*1024个事务,超了就报错啦。
一个undo log segment称为undo log或undo slot或undo;一个undo log对象对应多个undo log record,也就是记录的历史版本。
一个undo log segment有一个page链表,undo log record就是放在page中的,当一个page不足以放下新的undo log record时,会分配新的page,放到链表尾部。
一个undo log segment其实是一个页叫undo log header page,有INSERT/UPDATE两个类型。这个页有一项内容TRX_UNDO_PAGE_LIST是一个链表,即undo page链表。
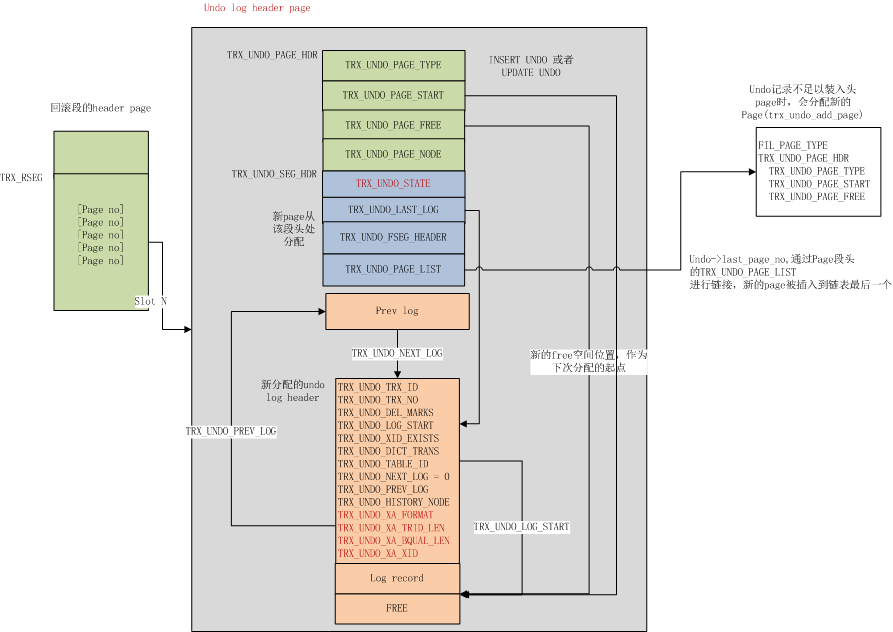
简单来说,结构是这样的:
- rollback segments(128)
- undo log segments(1024)
- undo page(N)
- undo record
- undo record
- …
- undo page(N)
- undo log segments(1024)
A collection of undo logs. Undo log segments exists within rollback segments. An undo log segment might contain undo logs from multiple transactions. An undo log segment can only be used by one transaction at a time but can be reused after it is released at transaction commit or rollback——mysql#undo_log_segment
一个rollback Segment可以被多个事务使用。而一个undo log segment只能被一个事务占有。由于undo log segment区分插入和更新,又区分临时表和普通表,所以一个事务至多占有四个undo log segment。
头
这张图里,
- Undo Log Segment Header:是undo log的第一页,不存放record
- undo log header:图里
Undo Log Segment Header的TRX_UNDO_LAST_LOG属性指向了一个undo page,每一个undo page都有undo log header描述这个undo page的信息。 - undo page header:图里没有,这个header类似于数据页的page header。
写undo log过程
分配回滚段
当读写事务开启或只读事务转化为读写事务时,会为一个事务分配事务id和一个回滚段(只读事务的id是0)。
分配逻辑:
- 轮询(环形缓冲,同redo log)选取一个可用的回滚段;
- 选取的回滚段引用计数+1(多对一),防止被回收(truncate)。
- 临时表使用临时表回滚段,特点是不用写redo log,普通表使用的普通回滚段需要写redo log。
使用回滚段
数据变更时,insert和update分别写相似但不同的undo log。
- 临时表不用写redo log
- 操作时未分配undo log statement,则对变更类型分配对应的undo log statement
- 分配undo log statement时,如果缓存列表有可用的undo log statement,取出来使用。
redo log有许多种类型,这里是一种type为MLOG_UNDO_INSERT的日志,保证undo log是有效的。
写入undo log
insert的undo record长这样

- type_cmpl:undo log类型,purge时用
- undo no:事务编号
- table id:表id
update的undo record长这样
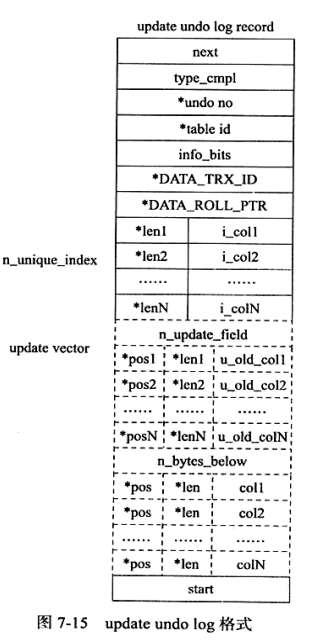
- DATA_ROLL_PTR:该行对应的前一个历史版本的指针,从而构建一个历史版本的链表
- type_cmpl:undo log类型,辅助purge线程清理
- (posN,lenN,u_old_colN)[]:字段旧值,只需要记录被更新的字段
- (pos,len,colN)[]:被更新的二级索引,回滚的时候需要
- undo no:事务编号
- table id:表id
事务no和事务id还是有些不同的,事务编号是用来排序的,在事务提交之前通过全局计数器生成,目的是为了放入histroy list有序,方便purge清理。
不同类型的undo record下有些属性没有,例如索引没变化的情况下,(pos,len,colN)[]就没记录。
(其实我不知道记unique key干嘛的)
undo log类型
purge线程在对待undo log时,会根据undo log的类型做不同的动作,下面分为三类,括号里是动作
- 插入:
- TRX_UNDO_INSERT_REC:表示新增记录(主键记入日志)
- TRX_UNDO_UPD_DEL_REC:当表中有一条被标记为删除的记录和要插入的数据主键相同时,实际是更新这条被标记删除的记录。(主键记入日志)
- 更新:
- TRX_UNDO_UPD_EXIST_REC:(将主键和被更新了的字段内容记入日志)
- 删除:
- TRX_UNDO_DEL_MARK_REC:(主键记入日志)标记删除
插入
插入时构建的undo log,包括undo类型,undo no,table id,主键各列信息。
insert undo log在事务提交后就会被删除。
更新
更新时构建的undo log,包括undo类型,undo no,table id,主键各列信息,data_trx_id、data_roll_pointer,被更新的二级索引,n_updated,字段旧值。
MVCC那篇讲过,每行记录都有三个隐藏字段,所以记录的old_trx_id、old_roll_pointer会被记入undo log,old trx_id表示修改的事务id,old_roll_pointer指向前一个undo record。
如果要更新一行记录的主键,需要删除记录(delete_mark置1,不能同步删除,为了MVCC),再插入新记录,所以会有TRX_UNDO_DEL_MARK_REC和TRX_UNDO_INSERT_REC两条日志。
对于二级索引的更新都是删除+插入。
如果更新一行前后的存储空间不一样大,也需要删除(同步删除)再插入。
删除
删除一条记录,其实分两个阶段,
- prepare阶段:将delete标志位置1,构造undo log
- purge阶段:这个发生在事务提交后,将记录移动到垃圾链表,等待复用。
垃圾链表是指数据页上的一个属性PAGE_FREE,指向一个链表的头节点,可以参阅文章底部的链接。
删除属于更新,所以他们的undo log是同一个数据结构,不过删除类型的undo log少了n_updated和字段旧值,以及被更新的二级索引。
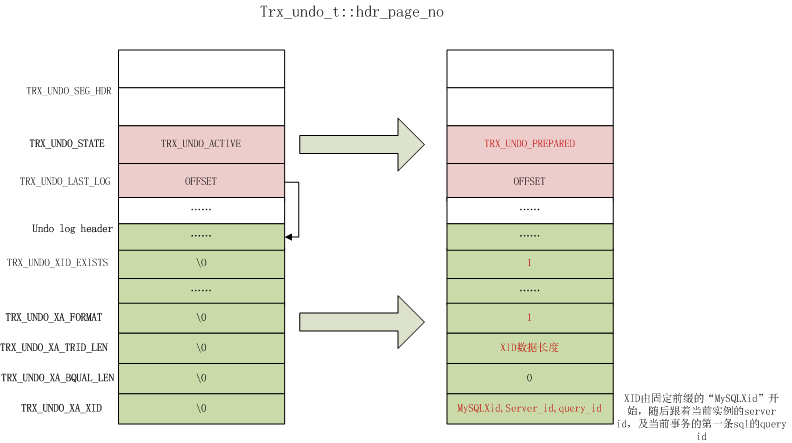
事务prepare
事务开始的阶段,需要将undo log header page的事务状态TRX_UNDO_STATE设置为TRX_UNDO_PREPARED
事务提交
先说一下history list,show engine innodb status执行这个命令我们可以看到history list
*** WE ROLL BACK TRANSACTION (1)
------------
TRANSACTIONS
------------
Trx id counter 2915975770
Purge done for trx's n:o < 2915975770 undo n:o < 0 state: running but idle
History list length 47
LIST OF TRANSACTIONS FOR EACH SESSION:
---TRANSACTION 421366361910208, not started
0 lock struct(s), heap size 1136, 0 row lock(s)
---TRANSACTION 421366361903824, not started
0 lock struct(s), heap size 1136, 0 row lock(s)
这个值表示还有多少undo log没被清理,这个值太大的话,说明有undo log由于有大事务存在而无法被清理。
Undo Log Segment Header有个TRX_UNDO_STATE,事务提交时,TRX_UNDO_STATE有三种值,
- 如果当前的undo log只占一个page,且占用大小使用不足其3/4时(TRX_UNDO_PAGE_REUSE_LIMIT),则状态设置为
TRX_UNDO_CACHED,该undo对象会随后加入到undo cache list上; - 如果事务类型是
TRX_UNDO_INSERT_REC,则状态设置为TRX_UNDO_TO_FREE - 如果不满足上面的,就需要purge线程去清理,状态设置为
TRX_UNDO_TO_PURGE
对于update undo对象需要放入history list上,具体是将当前undo加入到回滚段header的TRX_RSEG_HISTORY链表上。
如果update undo只有普通表,则给History list length+1,如果还有临时表,则+2,然后唤醒purge线程。
如果update undo需要缓存,则放入回滚段的update_undo_cached链表上;否则释放undo对象内存。
对于insert undo在事务释放锁、从读写事务链表清除、关闭read view后才进行,也就是等所有后事都办完才清理。
如果insert undo需要缓存,则放入回滚段的insert_undo_cached链表上;否则释放undo对象内存。和update undo不同的是,insert undo不需要放入hisotry list。
事务提交后,回滚段的引用计数-1。
tip1:由于cache的原因,即使db空闲中,history list的长度一般都不会是0。
tip2:insert undo的重用是直接reset,而update undo的重用是会和上一个事务的undo page共存的,具体是undo page上的undo log header有TRX_UNDO_NEXT_LOG 和TRX_UNDO_PREV_LOG来表示事务在页面中的偏移量的
清理 purge
purge发生在事务commit时。update undo会被放入history list中,当没有活跃的事务作用于undo log时,会被purge线程清理。如何判断有没有活跃的事务作用于undo log?innodb会快克隆一个活跃的最老的read view,所有在这个read view之前的undo log都是可以清理的。
purge线程从history list批量取到undo log后,对于in-place更新,需要看需不需要清理二级索引;对于删除操作,需要将删除记录放入数据页垃圾链表PAGE_FREE中。
回滚
事务回滚只需要拿到undo log的进行逆向操作就可以了。
对于标记删除的记录清理delete_mark;对于更新,将数据回滚到最老版本,回滚索引;对于插入操作,直接删除聚集索引(后)和二级索引(先)。
持久化
todo
崩溃恢复
其他篇。
后记
由于insert和update的种种区别,以至于undo log segment需要分成两种。