前言
有一次面试,面试官问我:mysql事务隔离级别有哪些? 我:balabala…… 面试官问:那可重复读是怎么实现的? 我:emm。。第一次读会有快照。。 面试官:嗯。。 我:。。。
然后呢,然后就不知道啦。
事实上,Innodb的RC和RR隔离级别下,读有**快照读(snapshot read)和当前读(current read)**之分,当前读就是SELECT ... LOCK IN SHARE MODE和SELECT ... FOR UPDATE,快照读就是普通的SELECT操作。
快照读的实现,利用了undo log和read view。
快照读不是在读的时候生成快照,而是在写的时候保留了快照。
快照读实现了Multi-Version Concurrent Control(多版本并发控制),简称MVCC,指对于同一个记录,不同的事务会有不同的版本,不同版本互不影响,最后事务提交时根据版本先后确定能否提交。
但是,Innodb的读写事务会加排他锁,不同版本其实是串行的,所以首先要指出的是,Innodb事务快照读不是严格的MVCC实现。
实现
隐藏字段
Innodb每一行都有三个隐藏字段,分别是DB_ROW_ID、DB_TRX_ID、DB_ROLL_PTR。
DB_ROW_ID:如果表没有设置主键,用来作为记录的主键,因为Innodb使用聚簇索引的方式存储,记录必须有主键。
DB_TRX_ID:记录修改这行记录事务的id。
DB_ROLL_PTR:指向这行记录的前一个版本。
undo log
多版本其实是用undo log来实现的,undo log听起来是做回滚使用的,没错,但是事务提交后undo log可不会立刻清除,它作为历史版本存在着。只有当前没有事务依赖在这行记录上时,mysql的清理线程才会清理掉无用的undo log。
insert操作的undo log在事务回滚或提交后就会删除,因为只有回滚会用到。
update、delete的undo log需要保留(可见delete只是逻辑删除,其实也是个update操作,逻辑删除后由后台线程清理)。
下面假设有一条记录如下,column_1、column_2初始值为1和2。
 假设这时有个三个事务ABC,A,C事务开始,对这条记录的查询结果如下:
假设这时有个三个事务ABC,A,C事务开始,对这条记录的查询结果如下:
| column_1 | column_2 |
|---|---|
| 1 | 2 |
接着A事务执行更新column_1为11;
具体过程是:给记录加X锁,复制记录为undo_log_1,然后再将记录的column_1改为11,DB_TRX_ID为A,DB_ROLL_PTR指向前一个版本。
虽然数据行和undo log画的一样,但实际undo log有自己的数据结构。
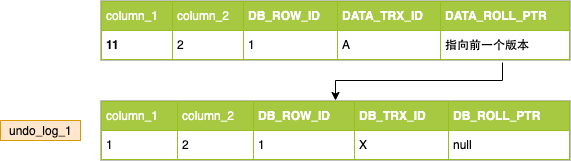 A事务提交,释放X锁。
A事务提交,释放X锁。
接着B开启事务,执行更新column_2为22;
具体过程是:给记录加X锁,复制A事务更新完的记录为undo_log_2,然后再将记录的column_2改为22,DB_TRX_ID为B,DB_ROLL_PTR指向前一个版本。
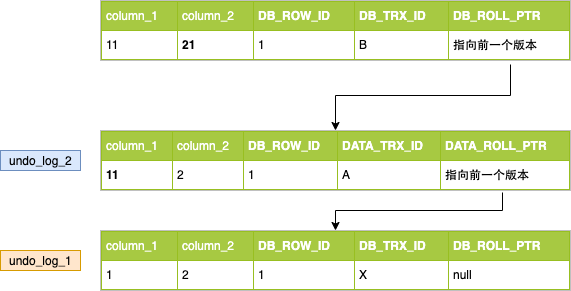 然后B事务提交。
然后B事务提交。
注意!!如果A事务没有提交,X锁是不会释放的,那么B事务对这行记录执行update为了获取X锁会阻塞住的,而MVCC标准各个版本应该是不会相互影响的,所以说Innodb事务快照读不是严格的MVCC实现。
那么问题来了,C事务这时执行第二次查询,查询结果会是什么呢。
read view
光有多版本还不够,需要一个机制对undo log进行可见性判断,决定当前事务读到的是哪个版本,这个机制就是通过read view完成,
read view是对当前系统中活跃的所有事务列表的封装,注意是所有事务,而不是作用于目标行的事务。
read view最早的事务id记为up_limit_id,最迟的事务id记为low_limit_id(low_limit_id = 未开启的事务id = 当前最大事务id+1),活跃事务id列表记为descriptors。
RC和RR的区别就是,RR在第一次查询会创建新的read view,RC是每次查询都创建read view。
如果记录上的
trx_id小于read_view_t->up_limit_id,则说明这条记录的最后修改在readview创建之前,因此这条记录可以被看见。如果记录上的
trx_id大于等于read_view_t->low_limit_id,则说明这条记录的最后修改在readview创建之后,因此这条记录肯定不可以被看见。如果记录上的
trx_id在up_limit_id和low_limit_id之间,且trx_id在read_view_t->descriptors之中,则表示这条记录的最后修改是在readview创建之后,被另外一个活跃事务所修改,所以这条记录也不可以被看见。如果trx_id不在read_view_t->descriptors之中,则表示这条记录的最后修改在readview创建之前,所以可以看到。基于上述判断,如果记录不可见,则尝试使用undo去构建老的版本(row_vers_build_for_consistent_read),直到找到可以被看见的记录或者解析完所有的undo。
上一节里,假设事务隔离级别是RR,事务id大小顺序是:X < C < A < B < D(D是未开启的事务Id),事务都是读写事务(只读事务不会加入read view)
那么C事务第一次查询创建一个read view,up_limit_id为C,low_limit_id为B,descriptors为{C,A},这时记录的DB_TRX_ID是X,A > X,说明记录可见。
当A事务更新完毕B事务更新完毕后,C事务执行第二次查询,read view还是最开始的那个,此时记录的DB_TRX_ID是B,>= low_limit_id, 因此这条记录肯定不可以被看见,需要沿着历史版本找。
记录的前一个版本的DB_TRX_ID是A,在up_limit_id和low_limit_id之间, 且在descriptors之间,所以此版本还是不可以被看见,继续往历史版本找。
前一个版本的DB_TRX_ID是X,< up_limit_id, 所以该版本可见,所以C事务第二次查询结果依旧是:
| column_1 | column_2 |
|---|---|
| 1 | 2 |
这就做到了可重复读。
如果是RC呢?
C事务执行第二次查询,创建新的read view,up_limit_id为C,low_limit_id为D,descriptors为{C},此时记录的DB_TRX_ID是B,在up_limit_id和low_limit_id之间,但是不在在descriptors之中,所以记录是可见的,也就是说C事务可以读到B事务提交的结果,这就是RC快照读的实现。
幻读
RR级别下,在一个事务里,如果全程只进行快照读操作,那么是不会发生幻读的,也不会加锁;如果事务进行快照读又进行了写操作,那么就会发生幻读。
也就是说:RR的幻读只发生在写操作中
可以用当前读解决幻读。
聚簇索引
聚簇索引在更新主键的时候,会删掉旧记录,插入带有新主键的记录。
二级索引
二级索引是没有隐藏字段的,所以没有undo log,只有一个标志位。
如果一个update语句更新到了二级索引,旧二级索引delete_mark置1,插入新二级索引。查询的时候,要判断可见性怎么办?根据二级索引找到聚簇索引(无视delete_mark),再从聚簇索引开始可见性判断,找到可见记录,如果可见记录和二级索引维护的结果一致(索引值和主键值一样),就返回记录,否则返回空。
这样效率比较低,比如student表里age是二级索引,查询条件是age=10,满足这个条件的age->student_id的二级索引会有多个,事务事务需要遍历所有age=10的索引进行可见性判断才能拿到旧值。
于是innodb给二级索引加了个MAX_TRX_ID记录最后更新二级索引的事务,如果当前事务read_view的 up_limit_id > MAX_TRX_ID,说明在创建read_view时最后一次更新二级索引的事务已经结束,就可以无视delete_mark=1的二级索引。如果MAX_TRX_ID失效,依旧要遍历所有age=10的二级索引。
题外话
在InnoDB里面有两种事务模式,一种是读写事务,就是会对数据进行修改的事务,另外一种是只读事务,仅仅对数据进行读取。开启一个读写事务要做的事比开启一个只读事务多许多,需要分配回滚段来记录undo log,需要把读写事务加入到全局读写事务链表,把事务id加入活跃读写事务数组中,所以你的事务没有写操作的话,声明为只读事务是个不错的优化。
5.6 如果要开始只读事务,需要显式指明事务模式为只读;
5.7如果不指明事务模式,mysql会初始化为只读事务,如果发生写操作,再将事务提升为读写事务,分配回滚段,分配事务id(只读事务也有id啦),加入读写事务链表。 5.7如果一次read view使用完后,没有新的读写事务创建,那么可以给下一个事务复用。
还有性能,由于读是不加锁的,RR似乎比RC开销小,那是不是RR的性能比RC好?事实是不一定的,在写的时候,RR为了防止幻读,加入了gap和next-key锁,这通常是RR会造成死锁,导致RR比RC差的原因。
后记
在这之前,不明白为什么事务可以临时指定隔离级别,临时指定不需要其他事务配合么,现在应该懂了😎,不过事务还有好多不懂😎