前言
为了学习etcd,先学习了解一下Raft协议,想总结一下Raft和zookeeper的ZAB协议协议的异同。
ZAB是对PAXOS算法的改进(没看过PASXOS,好像没有leader概念,我直接看的ZAB),增加了leader、follower、learner的角色。
Raft自称是比PAXOS更容易理解的一致性算法,和ZAB一样有leader、follower,而且一个强leader的算法。
时间
Raft:使用任期term表示一个选举轮次。
ZAB:使用electionEpoch表示一个选举轮次。
选举
投票
Raft:忽略上一轮投票。选举过程只能进行一次投票,如果投过票了,收到投票请求就会无视。这样越早发起投票的人越有可能当leader;同时,也可能出现每个节点都没有收到majority的投票,出现投票被瓜分的情况。Raft采用设置随机的选举超时时间来解决投票被瓜分。
ZAB:忽略上一轮投票。每次收到投票请求都会进行判定,然后若自己的投票有变,会重新通知所有节点。这样不会出现投票被瓜分,但是时间会比Raft多很多,导致服务可用性降低。
投票pk
Raft:term大的胜出,相同时index大的胜出
ZAB:electionEpoch大的胜出,相同时zxid大的胜出
投票结果
Raft:每个节点都只有自己的投票结果,如果发现自己投票过半,要通知所有节点,并发送心跳,心跳间隔 < 选举超时时间.
ZAB:每个节点保存所有节点的票根信息,每个节点收到投票请求后都会检查是否有过半的票根,如果有,会和leader建立起一个连接,leader会发送心跳。
选举结束
Raft:选举完可以立刻提供服务,对于节点不一致的问题,Raft靠接下来附加条目RPC来逐渐修复。按论文说的5台节点的集群,重新选举完成的时间平均是35ms,最长是150ms(选举超时时间配置为12-24ms)。
ZAB:选举完得完成日志同步才能对外提供服务,而且ZAB的选举可能长达秒级的时间,导致服务可用性降低。
分区容错性
当 可用节点 > N/2,Raft和ZAB的集群都是可用的。
客户端请求
读(针对读请求落到follower的情况)
Raft:Raft的读其实有几个方案
- 强一致读:转发给leader;leader插入一个空日志获得readIndex;心跳广播(确认自己是leader,才能拥有最新日志);等待状态机applyIndex经过readIndex(同步最新日志条目);返回给follower;返回给客户端;
- 在follower读:从leader获得readIndex;等待applyIndex经过readIndex;查询自身状态机;(从leader获得readIndex时,leader也要进行心跳广播)
- 折中方案:leader在接受到majority心跳响应后一段时间内不广播,这是论文作者不推荐的,因为“响应后一段时间内”这个时间可能是不准确的。
ZAB:follower直接返回,如果一个follower和leader未同步完成,follower返回的是脏数据,如果要保证数据最新,需要客户端调用sync()方法同步数据,正常情况下ZAB只保证最终一致性。
写
主要流程
Raft:
- 转发给leader;
- leader将请求封装为entries,写入日志,得到在日志中的index,连同entries发送给followers,注意这可以是批量的
- follower执行接收逻辑,如果成功写入文件,返回true
- leader收到过半成功回复就更新
committIndex,把entries应用到状态机中,回复客户端 - leader下次心跳会带上
committIndex的值用leaderCommit表示,followers发现leaderCommit大于自己维护的committIndex,就令commitIndex等于leaderCommit和 新日志条目索引值中较小的一个
ZAB:典型的两阶段提交
- 转发给leader
- leader封装为一个
proposal,写入日志,发送给followers - follower执行接收逻辑,如果成功写入文件,返回true
- leader收到过半成功回复就提交
proposal,同时广播一个commit消息,通知followers提交提议
接收逻辑
Raft:如果prevLogIndex和prevLogTerm不匹配,返回false,由leader调整,从而达到在写请求再同步数据的目的
ZAB:没有什么特别的,接收到proposal写入文件,接收到commit提交日志
旧leader数据
这个是指旧leader崩溃后,新leader对旧数据的处理
Raft:保守,过半或未过半日志都是未提交。只能提交当前term的日志,如果提交了当前日志,那么旧term的日志也会被一波提交(旧term的日志只能被间接提交)。允许出现未提交的数据被覆盖。
ZAB:激进,过半或未过半日志都被提交,由zookeeper选举完成后的数据同步完成。
leader假死
Raft:leader和follower是没有连接的。旧leader假死后,新leader诞生,旧leader复活后发送带有旧term的RPCs,follower收到之后返回新term给旧leader,旧leader更新term,加入follower大军。
ZAB:leader和follower存在连接。旧leader假死后,连接断开,旧leader进入LOOKING状态,从集群中学习投票结果/重新选举,最终找到leader建立起连接。
请求异常
Raft:重试,Raft要保证RPCs是幂等的。
ZAB:follower和leader断开连接,重新加入集群
挂了的机器加入一个选举完成的集群(不是新加机器)
Raft:leader会对follower进行RPCs重试,所以恢复的follower会收到leader的心跳请求。
ZAB:恢复的follower会学习集群中的投票结果,可以识别到leader
日志复制的顺序
Raft:由leader维护log顺序。如果follower重启,不会阻塞leader写入请求,会按照leader顺序追赶日志;如果leader挂了,新leader也可以将旧term、新term日志按顺序提交。
ZAB:由leader维护log顺序。如果follower重启,会获取leader读锁,leader阻塞写入请求,接着追赶差异,获取leader已提交proposal和未提交proposal,然后再释放leader读锁;如果leader重启,新leader选举后会进行数据同步
集群成员变更
集群配置不能一下子全切换,否则同一个时期可能会出现两个leader。
Raft:使用两阶段变更。旧配置为C-old,新配置为C-new,C-old-new表示中间配置。配置变更命令由客户端发起,leader以log传播C-old-new,等C-old-new提交之后,再广播C-new配置,这时不在C-new里的机器就要自觉退出。Raft论文参与者后来还提出一个一阶段变更,提出限制一次变更只能添加或删除一个成员来简化问题,如果要变更多个成员,需要执行多次成员变更。
ZAB:3.5版本以前是停机的,但停机变更也有问题,3.5开始使用了动态变更成员,出门左转Zab协议中的动态成员变更,比Raft难理解😐,反正我是看不下去😐。
总结
Raft是在想解决PAXOS过于复杂的缺点的背景下提出来的一个一致性算法,之前也看过ZAB协议,感觉Raft可用性比ZAB高很多。
不过有个问题让我迷惑是,在两阶段成员变更方案里,如果提交了C-old-new后,还有旧的Server1,Server2没有复制到,Server1,Server2的配置还是C-old
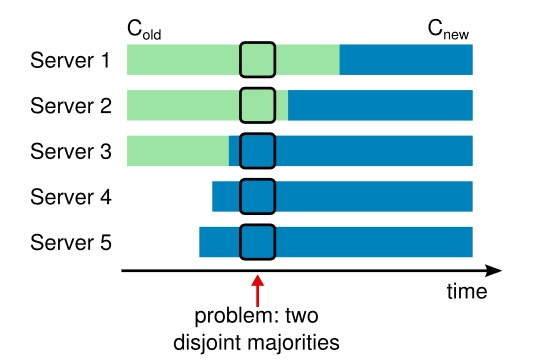 这时候Server1,Server2发生了网络分区,那么这两台服务器还是可以产生基于
这时候Server1,Server2发生了网络分区,那么这两台服务器还是可以产生基于C-old的leader,而Server3,Server4,Server5形成另一个majority,也可以产生一个leader,不一样还会出现双leader问题么?若使用一阶段成员变更,就可以阻止多个majority产生,杜绝这种情况吧。
很有兴趣实现一个Raft算法。