不停计算的机器
理解YEMU如何执行程序
(只画出了有变化的部分,每一行的状态是注释里的指令执行后的状态
R[0] 0000 0000 R[1] 0000 0000 // init
R[0] 0001 0000 R[1] 0000 0000 // load 6# | R[0] <- M[y]
R[0] 0001 0000 R[1] 0001 0000 // mov r1, r0 | R[1] <- R[0]
R[0] 0010 0001 R[1] 0001 0000 // load 5# | R[0] <- M[x]
R[0] 0011 0001 R[1] 0001 0000 // add r0, r1 | R[0] <- R[0] + R[1]
R[0] 0011 0001 R[1] 0001 0000 M[7] = 0011 0001 // store 7# | M[z] <- R[0]
RTFSC(2)
立即数背后的故事
如果把内存地址按栈摆放就是这样,解释指针时是从低地址往高地址解释的,所以小端在数值转换比较方便,比如32位数0x1234要解释为8位数字,只需要解释指针的时侯取第一个字节即可。
+----+
x+3 | 00 |
+----+
x+2 | 00 |
+----+
x+1 | 12 |
+----+
x | 34 |
+----+
- 运行在Motorola 68k架构的处理器时,读取立即数应该按数据宽度读取n个字节,然后将字节数组逆序,按大端存储
- 模拟Motorola 68k架构时,读取立即数应该按数据宽度读取n个字节,然后将字节数组逆序,按小端存储
立即数背后的故事(2)
指令长度只有32位,盲猜是用分页的思想,把低位和高位拆开,一部分放寄存器里,利用寄存器做索引。(待求证
高位低位拆开,然后用一个加法相加
RTFSC理解指令执行的过程
基本就是下图的流程不停地重复,
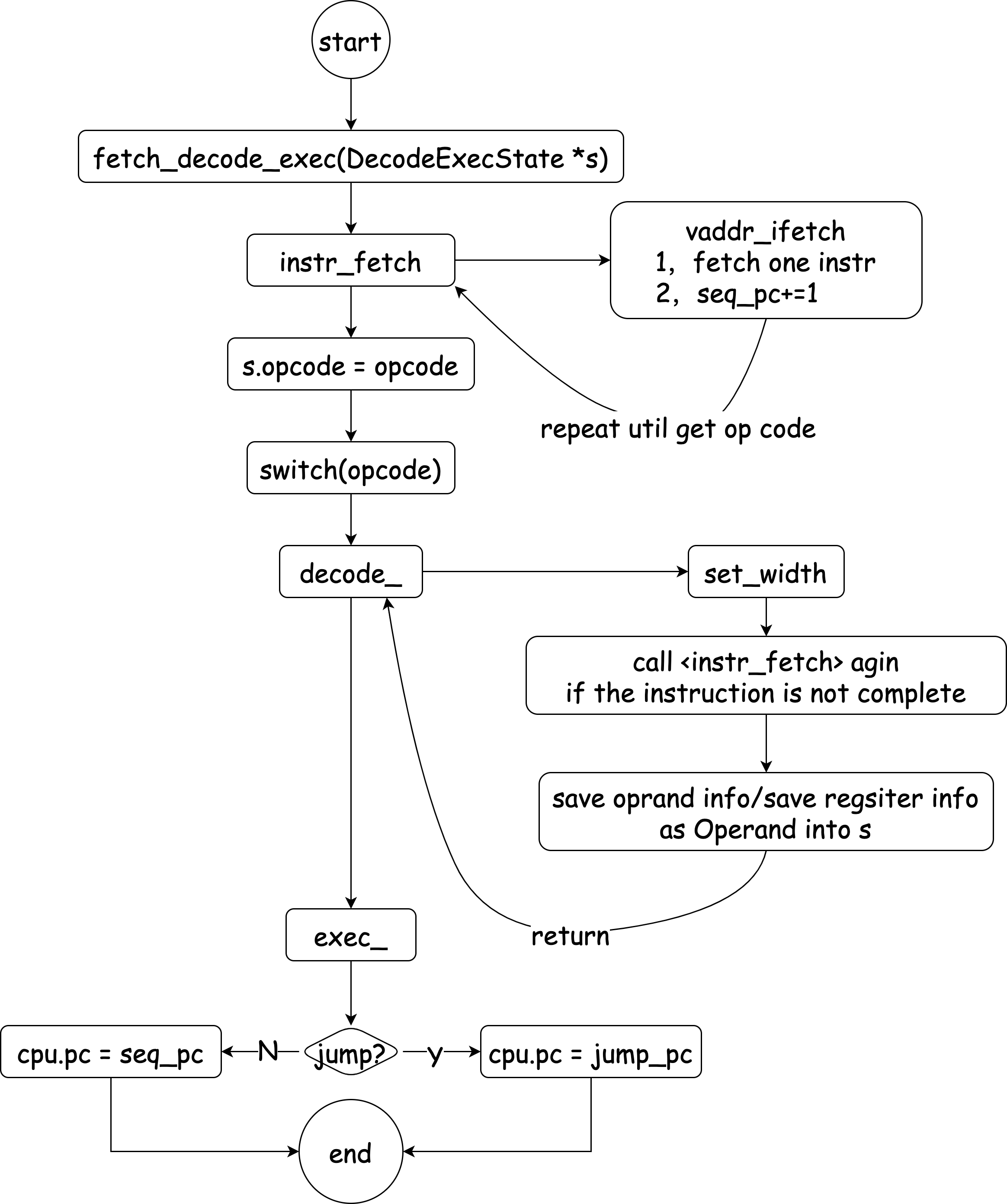
(其实这是x86的,虽然x86的指令基本实现完了,但当我用QEMU死活跑不了difftest后,我就转战riscv32了😊)
准备交叉编译环境
apt-get install g++-riscv64-linux-gnu binutils-riscv64-linux-gnu
为什么执行了未实现指令会出现上述报错信息
流程图switch(opcode)这一步,如果没有实现对应指令,会走到default分支,执行exec_inv
运行第一个客户程序
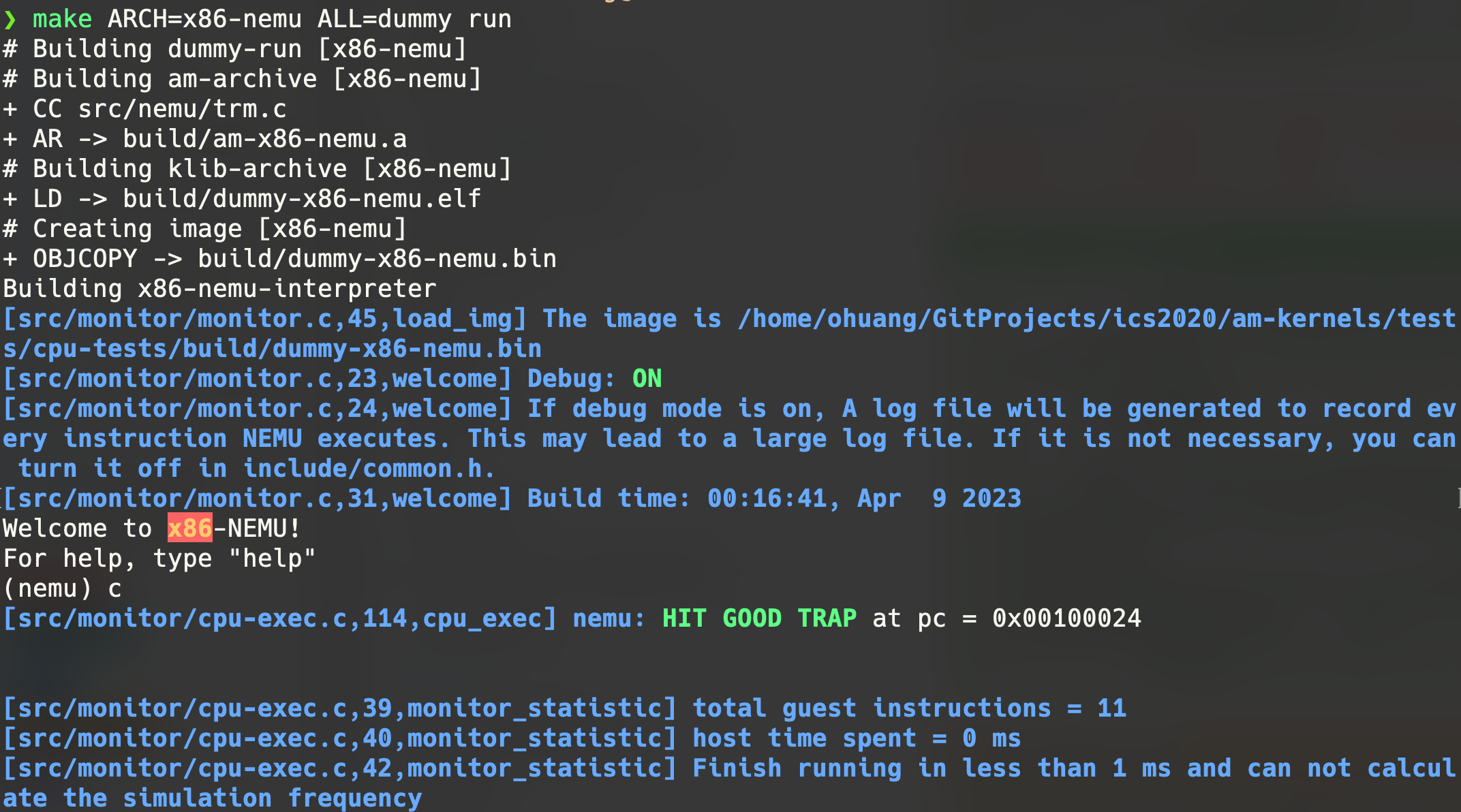
其他
数的扩展
由于NEMU的数据宽度都是用word_t/sword_t,带符号数应该用sword_t表示。riscv32的sword_t是4个字节,如果操作数不是4个字节,需要做符号扩展,用到的rtl函数是rtl_sext,可以利用位域来实现,用到的宏是
#define SEXT(x, len) ({ struct { int64_t n : len; } __x = { .n = x }; (int64_t)__x.n; })
其中len是最高位的位置(从1开始)
HIT BAD TRAP
各种编码的小马虎,都可能会导向HIT BAD TRAP,所以手册指令描述应该看仔细,可以少走弯路。
第四节的基础设施有DiffTest,可以每次执行一条指令就和大腿对比,如果不一致就报错。
但是,DiffTest没法对比内存(理论上可以对比,但是不现实)。所以在load出现DiffTest失败时,排查是比较困难的,有可能是在load行为出错,也有可能是store行为出错。
所以指令实现要谨慎,否则一出错就得查找好久。
真的出错时,先检查load指令,否则就用watchpoint大法检查store行为是否正确。
解析指令
写了个riscv命令用于解析riscv指令,效果如下:
(nemu) riscv f61ff0ef
1111011 ????? ????? 111 ????? 1101111
mulh
同有符号加法一样,有符号乘法也是把负数用补码表示,免去了单独计算符号位的问题,这也是有符号运算和无符号计算的区别,无符号计算开箱即用,有符号数需要先对负数转补码(正数的补码即原码,无需转换)
程序, 运行时环境与AM
这又能怎么样呢
这种设计原则其实是DIP依赖反转原则,遵循这个原则就可以做到解耦。具体地,高层次不应该引入低层次的逻辑,高层次和低层次之间的沟通应该通过抽象来完成,在这个场景下这个抽象就是halt()。
为什么要有AM? (建议二周目思考)
All problems in computer science can be solved by another level of indirection
AM提供提供了访问硬件的api以及一个简单的stdlib实现,充当了客户程序和目标架构的中间层,这个目标架构可以是$ISA-nemu,可以是native。
你可以基于AM移植其他程序,甚至移植一个操作系统(nanos-lite)。移植的程序不用管具体架构,只需要调用AM的API即可。
vmware也是虚拟机,为什么我们使用时不需要重新编一个iso镜像?因为vmware没有跨isa。如果跨了isa,你想在m1的mac上运行一个x86程序,通过vmware是不行的,而通过交叉编译和qemu你就可以做到。
stdarg是如何实现的?
这个头文件最常用用于可变参数解析
最常见的参数函数传递方式就是用寄存器/栈传递参数,按参数列表从右到左的顺序压栈。
一般可变参数都有一个参数用于表明参数个数,比如printf的format就通过转义符号指示了参数个数和类型(这也是为什么printf使用有错误的话可以在编译期报错)。知道了参数个数,我们就可以从寄存器/栈按顺序移动指针,按类型取出参数了。
如果没有stdarg, 而是用
&fmt + 1的方式取参数, 就会写出不可移植的代码, 比如x86_64就不是完全用栈传参数的.
基础设施
消失的符号
宏替换后就不在了,所以宏不是符号(当然宏可以产生符号
参数通过栈和寄存器传递,所以不需要符号
寻找"Hello World!"
先产出目标文件hello
然后hd查找elf文件的"Hello World!“地址
再执行
readelf --section-headers hello
确定字符串的地址,可以从section header里找到这个地址属于.rodata节,可以用以下验证
❯ readelf -p .rodata hello
String dump of section '.rodata':
[ 0] Hello World!
.rodata(read-only data)放的是常量数据
实现ftrace
如果你选择的是riscv32, 你还需要考虑如何从jal和jalr指令中正确识别出函数调用指令和函数返回指令
jal和jalr指令的rd寄存器是ra时,可以看作call的实现,这是riscv的调用约定jalr的rs1寄存器是ra时,可以看作ret的实现
不匹配的函数调用和返回
当尾调用优化生效时,可能会导致call和ret位置不匹配(但次数还是匹配的), 简单地说,因为没有新栈帧的需要,所以直接用跳转指令代替call, 接着函数执行完毕后,因为ra(返回地址寄存器)存的还是上一个函数的,所以会跨函数返回。
冗余的符号表
- 能执行成功
- 不能链接成功,报错:
(.text+0x20): undefined reference to `main`
链接是需要依靠符号表来定位定位符号的位置,如果没有符号表,如上面的例子,gcc不知道main函数在哪个位置,也就不知道程序的入口应该从哪里开始,无法完成链接。
如何生成native的可执行文件
以am-kernels/tests/cpu-tests/tests/string.c为例,不同的ARCH传入Makefile后,可以用于路由到不同的Makefile(abstract-machine/scripts),主要是是编译的源文件有区别。
编译ARCH=native用的是gcc套件,入口就是镜像的main,所以native不会有NEMU的那些输出(其实init_platform() 会比main更早执行,因为这个函数标注了__attribute__((constructor)))
编译ARCH=riscv32-nemu用的是riscv-gnu-toolchain,入口是NEMU的main,然后再从镜像作为数据,从main解释执行(用riscv32的方式解释)
P.S. 编译ARCH=$ISA-nemu的镜像时,即使用了-g、-ggdb3选项,gdb也读取不了调试信息。想对镜像本身调试的话,只能通过NEMU的基础设施或者使用ARCH=native。
这是如何实现的?
// abstract-machine/klib/src/string.c
#if !defined(__ISA_NATIVE__) || defined(__NATIVE_USE_KLIB__)
这一行的意思是,如果选择了非native架构,或选择native+klib,就要用自定义的stdlib实现
为什么定义了就能覆盖glibc实现?
通过make -n查看make过程,可以看到在编译klib单元的时候用上了-fno-builtin,man gcc可以看到这个选项的作用
Don’t recognize built-in functions that do not begin with _builtin as prefix.
事实上,如果你没有提供内置函数的实现,那么链接时还是会到glibc查找实现。
这里有个va_arg提取char的坑:https://stackoverflow.com/questions/28054194/char-type-in-va-arg
其实
klib实现的不够贴切标准也不重要,因为最终运行仙剑的时候用到的stdlib并不是我们这个klib🤓,当然,基本的功能还是需要实现的。
奇怪的错误码
可能注册了信号处理函数,执行了exit(1)(待求证
编写更多的测试(2)
用native+gblic的运行环境跑测试用例的结果,再用native+klib测试,最后用$ISA-nemu+klib测试
编写更多的测试(3)
略。
捕捉死循环(有点难度)
不能,正如像三维生物理解不了四维一样。
这其实是个著名的停机问题(Halting Problem), 其本质是程序无法自指(Self-reference)
不是
Self-contained哦
理解volatile关键字
_end应该是指终端。
volatile禁止指令重排序,如果去掉volatile,对*p的赋值代码可能会乱序,甚至消除掉这些无意义的代码。
如果_end是设备寄存器,设备会收到乱序数据甚至没收到数据。
P.S. volatile的语义在C和java里不完全一样,C里面的volatile语义简单的多,比如不保证内存可见性
理解mainargs
$ISA-nemu
在makefile参数转为宏,在静态变量展开
CFLAGS += -DMAINARGS=\"$(mainargs)\"
#ifndef MAINARGS
#define MAINARGS ""
#endif
static const char mainargs[] = MAINARGS;
native
// abstract-machine/am/src/native/platform.c
const char *args = getenv("mainargs");
halt(main(args ? args : "")); // call main here!
从这里的环境变量获得(make的参数会作为进程的环境变量
RTFSC尽可能了解一切细节
make ARCH=riscv32-nemu mainargs=t run
RTFSC了解一切细节
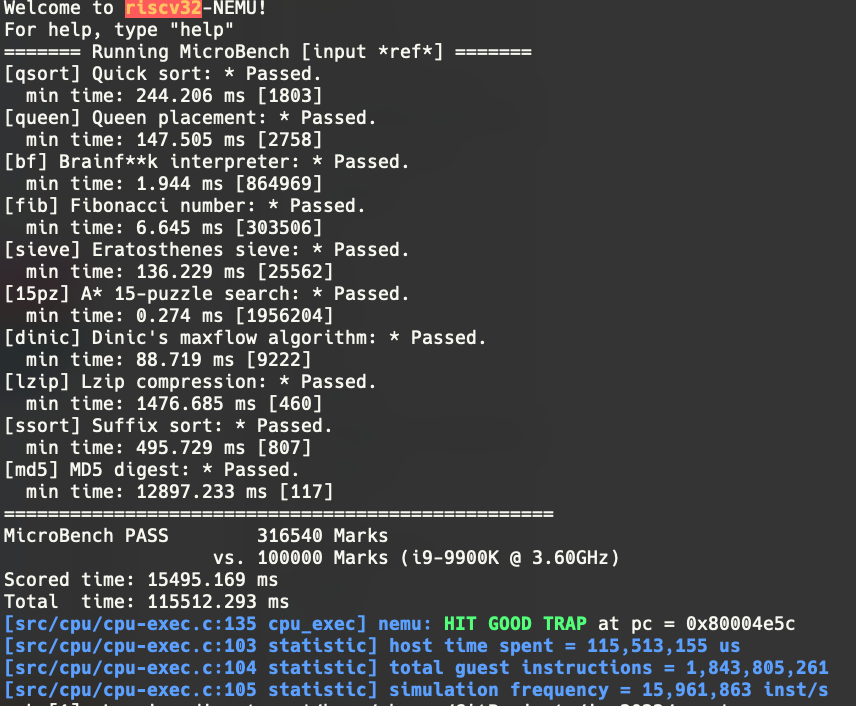 跑分这么高,看来我很牛逼(误
跑分这么高,看来我很牛逼(误
下面是native跑分

得来找找哪里有问题,以免迷失自我。分数有问题,那大概是获取的时间有问题,直接用difftest的思想,祭出printf大法对比NEMU的值和AM的值,两个地方的输出果然不一样。
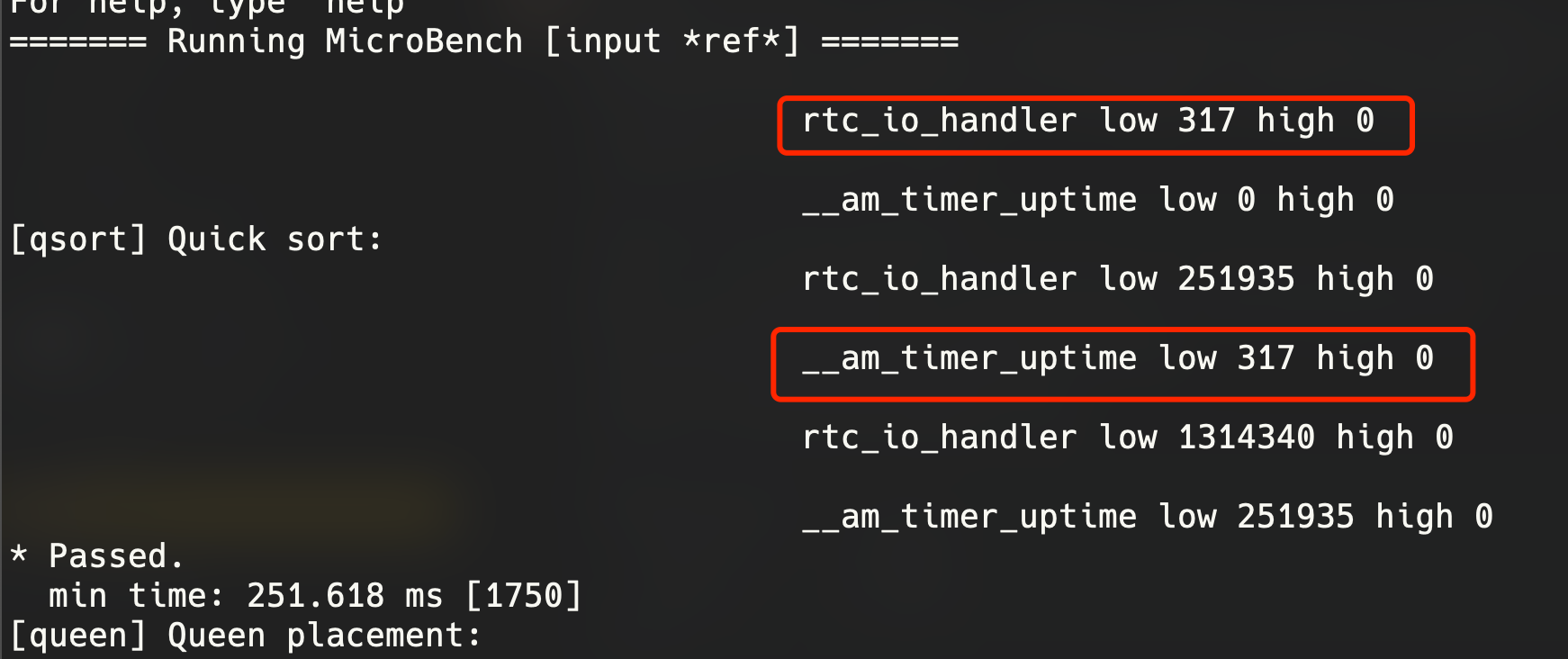
看起来AM每次读到的值都是NEMU上一次读到的值
AM代码:
void __am_timer_uptime(AM_TIMER_UPTIME_T *uptime) {
// 这里us和rtc_io_handler里的us不一样
uptime->us = (uint64_t) inl(RTC_ADDR) | ((uint64_t) inl(RTC_ADDR + 4)) << 32;
}
NEMU代码:
diff --git a/nemu/src/device/timer.c b/nemu/src/device/timer.c
index 2aff819..f1f02d6 100644
--- a/nemu/src/device/timer.c
+++ b/nemu/src/device/timer.c
@@ -21,7 +21,7 @@ static uint32_t *rtc_port_base = NULL;
static void rtc_io_handler(uint32_t offset, int len, bool is_write) {
assert(offset == 0 || offset == 4);
- if (!is_write && offset == 4) {
+ if (!is_write && offset == 0) {
uint64_t us = get_time();
rtc_port_base[0] = (uint32_t)us;
rtc_port_base[1] = us >> 32;
这里判断了offset的值防止连续的更新。因为AM先读的低字节的,导致没有更新低字节寄存器。
实现IOE(2)
最高位是keydown, 其余位是keycode
void __am_input_keybrd(AM_INPUT_KEYBRD_T *kbd) {
int k = inl(KBD_`ADDR`);
kbd->keydown = (k & KEYDOWN_MASK ? true : false);
kbd->keycode = k & ~KEYDOWN_MASK;
}
记得把VGA的所有选项打开。。不然没有屏幕。。
如何检测多个键同时被按下?
键盘输出一次只有一个,每次接受到输入事件时,把keycode缓存到队列里,短时间内队列里的按键视为一个组合。
神奇的调色板
只要改变需要淡入淡出的那部分索引的颜色板,就可以实现淡入淡出
实现IOE(3)
同步寄存器
当执行outl(SYNC_ADDR, 1);,会把同步寄存器映射的内存SYNC_ADDR写为1
在vga_update_screen判断vgactl_port_base[1]为1时,执行update_screen,并置为0。
屏幕大小寄存器
AM读取VGACTL_ADDR,由NEMU转发到vgactl_port_base[0]
display test
测试的确是执行成功了,但是FPS只有4。。。
最先想到的是memcpy,byte-by-byte的方式比较慢,因为选的是risv32,所以采取4字节批量复制的方式,最后再按字节复制。(即使一次复制8个字节,编译后也是按4个字节复制)
⚠️ 如果memcpy的src和dst不是4字节对齐的,直接拷贝会出现difftest失败,拷贝的结果是不正确的(TODO 还没搞懂,两段内存也没重叠)
优化完才7FPS。。。
游戏是如何运行的
struct character {
char ch;
int x, y, v, t;
} chars[NCHAR];
struct character: 字符状态。准确地说是个池子,申请新字符的时候,从池子挑一个可用的并随机一个字母赋值给ch。由于字符的width、height是固定的,只维护了(x,y)一个坐标,v是速度,每一帧y都要减去v,t在字符触底的时候会执行c->t = FPS,应该是表示让触底的字符暂留这么多帧。
texture[][][]: 文本表。三维分别是:Color, Letter, 字体位图(长度为CHAR_H*CHAR_W)
static int x[NCHAR], y[NCHAR], n = 0;: 上一次render的(x,y)列表,用于恢复背景色
运行过程
简单地说,这个游戏通过死循环:
- 根据帧号
frames更新chars字符状态 - 对
AM_INPUT_KEYBRD寄存器poll键盘事件,对chars对应的字符进行清除, - 将上一次
render的(x,y)列表恢复为背景色 - 根据
chars往AM_GPU_FBDRAW寄存器写入最新的字符图像
LiteNES如何工作?
当ARCH=riscv32-nemu时,nemu负责解释执行LiteNES,LiteNES负责解释执行rom,像是虚拟机嵌套虚拟机。(未求证
在NEMU上运行NEMU
读取按键
typing_game: io_read(AM_INPUT_KEYBRD) -> read from KBD_ADDR ->
nested-nemu: io_read(AM_INPUT_KEYBRD) -> read from KBD_ADDR ->
nemu: read from SDL lib
这里typing_game和nested-nemu都是运行在同一个进程里的,inl(addr)的不会死循环吗?
答案是不会,因为mmio是虚拟地址映射到真实地址,他们的真实地址是不同的。
刷新屏幕
typing_game: io_write(AM_GPU_FBDRAW, ...) -> write to FB_ADDR ->
nested-nemu: io_write(AM_GPU_FBDRAW, ...) -> write to FB_ADDR ->
nemu: write to SDL lib
必答题
编译与链接(static inline)
static inline声明,如果函数成功内联,起作用的只会是inline,而static inline是为了代码健壮性,防止有些编译器拒绝内联。这种情况static可以兜底把函数编译为local function。所以去掉inline不会报错,去掉static不一定会报错,去掉两者一定报错。
编译与链接()
- 通过
readelf可以统计到dummy的个数,带有默认镜像的riscv32-nemu是34个
❯ readelf -s build/riscv32-nemu-interpreter|grep dummy
35: 0000000000026900 4 OBJECT LOCAL DEFAULT 27 dummy
40: 0000000000026980 4 OBJECT LOCAL DEFAULT 27 dummy
49: 0000000000026a60 4 OBJECT LOCAL DEFAULT 27 dummy
53: 0000000000026aa0 4 OBJECT LOCAL DEFAULT 27 dummy
...
- 数量一样,因为没有初始化,声明是可以重复的。
- 会报重复定义,
error: redefinition of ‘dummy’。之前没遇到是因为用宏隔离了。
合影留念
虽然只有不到20FPS。先上线,后优化!
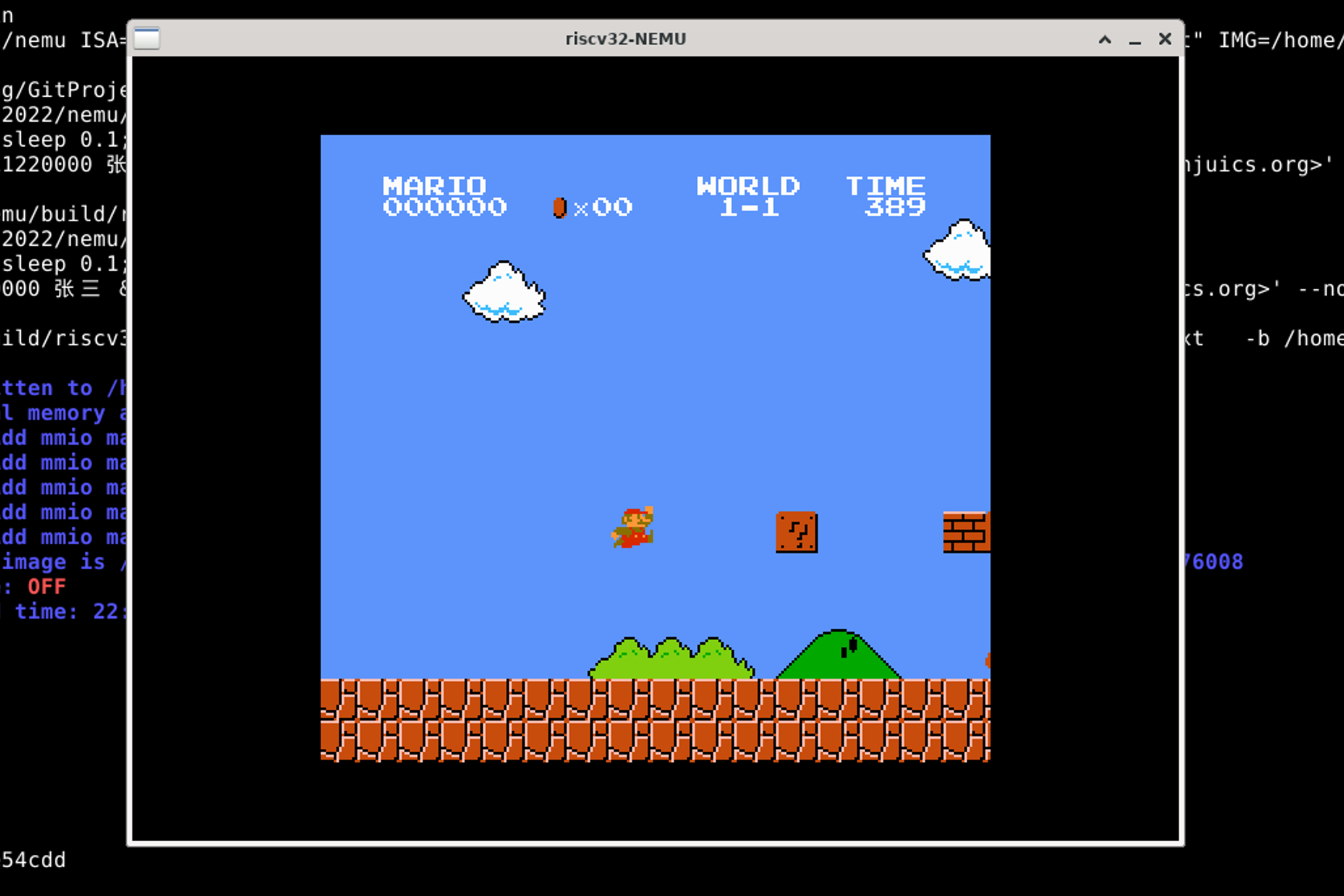
结尾
PA2结束,进入PA3