阳康复活,重拾实验!
穿越时空的旅程
特殊的原因? (建议二周目思考)
这些程序状态(x86的eflags, cs, eip; mips32的epc, status, cause; riscv32的mepc, mstatus, mcause)必须由硬件来保存吗? 能否通过软件来保存? 为什么?
这些是实时性很高的东西,会被频繁访问到,如果放软件里性能就太差了,每条指令都得去访存。
另一个UB
栈大小可以在链接脚本abstract-machine/scripts/linker.ld里面找到。
_stack_top = ALIGN(0x1000); // 将栈顶地址对0x1000对齐
. = _stack_top + 0x8000; // 栈大小为0x8000字节
_stack_pointer = .; // 栈顶指针
栈是从内存高地址到低地址的,所以栈底在0x8000
异常号的保存
不可以,因为x86是CISC(复杂指令集),而mips、riscv是RISC(精简指令集),一条指令无法容纳一个指针的长度。
对比异常处理与函数调用
- 触发不同: 异常处理是由异常事件触发的,函数调用是调用指令触发的
- 入口不同: 异常处理的入口是固定的异常处理程序,函数调用是多个函数入口
- 上下文不同: 异常处理会自动压栈参数,函数调用需要手动压栈
- 返回不同: 异常返回到异常发生处,函数调用返回到下一个指令地址
- 目标不同: 异常处理是为了修复异常状态,函数调用是为了执行功能
必答题(需要在实验报告中回答) - 理解上下文结构体的前世今生
在发生异常时,我们通过isa_raise_intr设置好CSR寄存器,然后进入__am_asm_trap函数,这段代码在trap.S文件里。
trap.S对32个寄存器和CSR寄存器压栈,形成一个Context结构体,然后跳转到__am_irq_handle处理函数
实现正确的事件分发
yield的异常号是11,系统调用号是-1。这是个自定义实现,因为yield()函数实现如下:
void yield() {
asm volatile("li a7, -1; ecall");
}
从加4操作看CISC和RISC
个人觉得交给软件做合适,CPU只负责执行指令,软件负责控制逻辑。
恢复上下文
__am_irq_handle当异常号为11时,mepc+4
必答题(需要在实验报告中回答) - 理解穿越时空的旅程
用户程序和系统调用
堆和栈在哪里
(好像前面问过了?
堆栈一家亲,他们边界定义在链接脚本abstract-machine/scripts/linker.ld里,堆&栈之间没有分界线。
如何识别不同格式的可执行文件?
文件有文件头,文件解析器会根据文件头去解析。但是文件头是可以直接修改的,所以可能会解析失败。
冗余的属性?
顾名思义,FileSiz就是数据在文件的大小,MemSiz就是数据在内存的大小,前者是已初始化的数据大小,后者包含了未初始化的数据。
为什么要清零?
为什么需要将 [VirtAddr + FileSiz, VirtAddr + MemSiz) 对应的物理区间清零?
我想主要是安全问题:
- 这段内存可能有上一个程序的恶意代码
- 这段内存可能有上一个程序的敏感数据
实现loader
具体loader应该做什么,讲义已经贴出传送门(W.7 PROCESS LOADING)
其实过程很简单,ELF从两个视角组织一个可执行文件:
- 一个是面向链接过程的
section视角,这个视角提供了用于链接与重定位的信息,例如符号表 - 一个是面向执行的
segment视角,这个视角提供了用于加载可执行文件的信息,我们要从这下手
segment在ELF里被抽象为Program Headers,我们只要先提取ELF的Elf32_Ehdr/Elf64_Ehdr,得到Elf32_Phdr/Elf64_Phdr的偏移量。
再根据偏移量提取Phdr数组,如果满足phdr.p_type == PT_LOAD,就需要装载到内存对应的位置,并将[VirtAddr + FileSiz, VirtAddr + MemSiz)清零。
检查ELF文件的魔数
❯ readelf -a ramdisk.img
ELF Header:
Magic: 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00
提取elf header,对比e_ident的头4个字节
assert(*(uint32_t *)elf->e_ident == 0x464c457f);
由于解释为uint32_t,按小端排序,字面量应该是0x464c457f而不是0x7f454c46
检测ELF文件的ISA类型
EXPECT_TYPE定义如下
#if defined(__ISA_AM_NATIVE__)
# define EXPECT_TYPE EM_X86_64
#elif defined(__ISA_X86__)
# define EXPECT_TYPE EM_386
#elif defined(__ISA_RISCV32__) || defined(__ISA_RISCV64__)
# define EXPECT_TYPE EM_RISCV
#elif defined(__ISA_MIPS32__)
# define EXPECT_TYPE EM_MIPS
#else
# error Unsupported ISA
#endif
将Nanos-lite编译到native
nanos-lite的实现应该是架构无关的,我们切换到native后,就可以专心用gdb调试我们的nanos-lite实现了
系统调用的必要性
不是必须,因为批处理系统的程序是串行执行的,不会存在资源抢占情况。
但是直接暴露给应用程序仍有些不妥,最主要的就是降低了程序的可移植性,比如你在nanos-lite上运行的程序,无法在真机运行,反之亦然。
识别系统调用
注意:异常号和系统调用号是两个东西。mcause寄存器存放的是异常号,a7存放的是系统调用号。
__am_irq_handle负责识别异常,do_event负责识别系统调用。
实现SYS_yield系统调用
RISC-V系统调用号的传递
因为a0-a7是calling convention里传递参数的寄存器。
在PA4里我们可以看到内核线程传参也是也用到了上下文,如果用a0传递系统调用号会增加设计复杂度。
man syscall可以看到Architecture calling conventions
实现strace
在do_syscall打印即可,为了方便控制,我在nanos-lite/src/syscall.h加了个宏开关
// #define STRACE
#ifdef STRACE
#define SLog(format, ...) \
printf("\33[1;35m[%s,%d,%s] " format "\33[0m\n", \
__FILE__, __LINE__, __func__, ## __VA_ARGS__)
#else
#define SLog(format, ...)
#endif
在Nanos-lite上运行Hello world
Newlib帮我们做好format工作了,所以我们专心实现write功能,因为fd目前只有1和2,我们加上assert防止后面忘了实现
static int write(int fd, void *buf, size_t count) {
assert(fd == 1 || fd == 2);
assert(count > 0);
for (int i = 0; i < count; i++) {
putch(*((char*)buf + i));
}
return count;
}
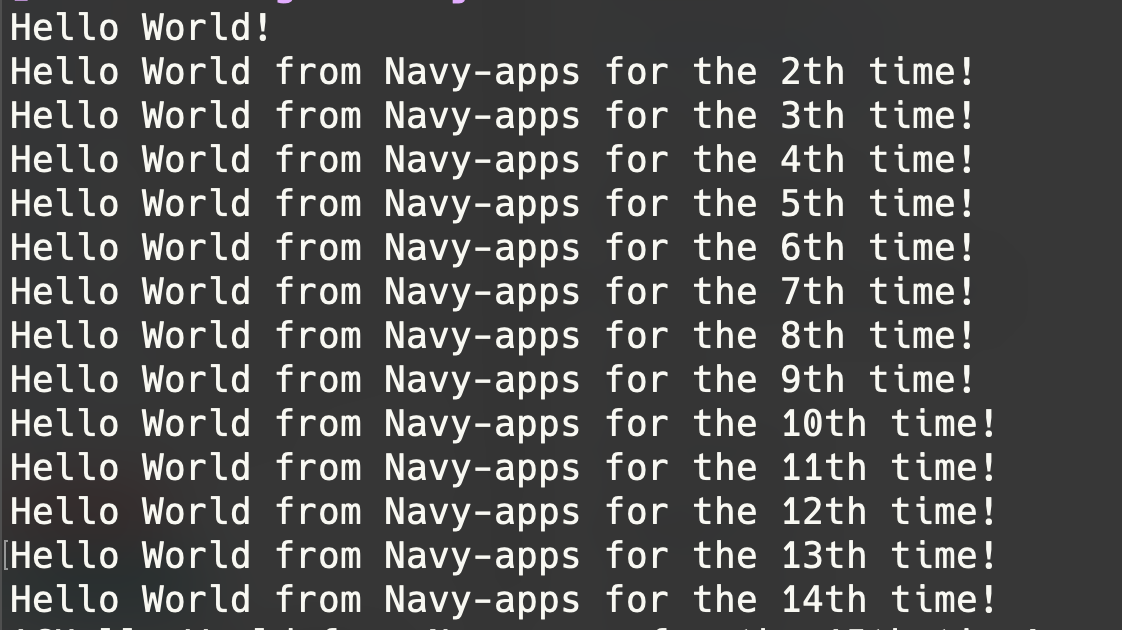
成功运行
实现堆区管理
extern char end;
static intptr_t cur_brk = (intptr_t)&end;
void *_sbrk(intptr_t increment) {
intptr_t old_brk = cur_brk;
intptr_t new_brk = old_brk + increment;
if (_syscall_(SYS_brk, new_brk, 0, 0) != 0) {
return (void*)-1;
}
cur_brk = new_brk;
return (void*)old_brk;
}
注意: 数据段结束位置可以用end或者_end
必答题(需要在实验报告中回答) - hello程序是什么, 它从而何来, 要到哪里去
我们知道
navy-apps/tests/hello/hello.c只是一个C源文件, 它会被编译链接成一个ELF文件. 那么, hello程序一开始在哪里? 它是怎么出现内存中的? 为什么会出现在目前的内存位置? 它的第一条指令在哪里? 究竟是怎么执行到它的第一条指令的? hello程序在不断地打印字符串, 每一个字符又是经历了什么才会最终出现在终端上?
我们运行hello程序的时候,实际是在运行nanos-lite。
首先我们需要在navy-apps里编译好一个镜像(就是一坨ELF二进制),然后cp到nanos-lite指定位置(build目录下)用于构建nanos-lite。
接着make ARCH=$ISA-nemu的时候会根据nanos-lite/src/resources.S重新生成.o文件,这个过程是通过对.S文件执行touch命令实现的。
resources.S文件声明了两个符号ramdisk_start,ramdisk_end,我们就是根据这个位置找到ELF文件实现loader。
load行为过后,代码就加载到内存的预期位置了,第一条指令也就是预期位置的指令。
打印字符从printf开始(这是Newlib实现的,不是我们AM里的klib实现了)。
开启strace日志,
[/home/ohuang/GitProjects/ics2022/nanos-lite/src/loader.c,56,naive_uload] Jump to entry = 0x83004e74
Hello World!
[/home/ohuang/GitProjects/ics2022/nanos-lite/src/syscall.c,38,do_syscall] sys_write(1, 830056fc, 13)
[/home/ohuang/GitProjects/ics2022/nanos-lite/src/syscall.c,42,do_syscall] sys_brk(83006cf0)
[/home/ohuang/GitProjects/ics2022/nanos-lite/src/syscall.c,42,do_syscall] sys_brk(83007000)
Hello World from Navy-apps for the 2th time!
[/home/ohuang/GitProjects/ics2022/nanos-lite/src/syscall.c,38,do_syscall] sys_write(1, 830068e0, 45)
Hello World from Navy-apps for the 3th time!
printf是带缓冲的,我们可以看到printf触发了sbrk系统调用申请了一块堆内存。
进行format行为之后,接下来是会调用write系统调用,发生异常,执行流交给操作系统,由操作系统把字符打印到终端上。
土川的思考
系统调用的strace用到了printf,我们知道了printf会触发系统调用,那么这会不会导致死循环?
答案是不会,strace用到的printf是AM的klib实现。
支持多个ELF的ftrace
就多传几个elf,多解析几次
文件系统
文件偏移量和用户程序
把偏移量放在文件记录表中,会导致多次打开同一个文件都是同一个偏移量,不过这里约定多次打开文件都是同一个fd,也就无所谓了。
让loader使用文件
给文件加个open_offset
diff --git a/nanos-lite/src/fs.c b/nanos-lite/src/fs.c
index a9d2670..b9f634f 100644
--- a/nanos-lite/src/fs.c
+++ b/nanos-lite/src/fs.c
@@ -9,6 +9,7 @@ typedef struct {
size_t disk_offset;
ReadFn read;
WriteFn write;
+ size_t open_offset;
} Finfo;
最后loader的代码为
static uintptr_t loader(PCB *pcb, const char *filename) {
int fd = fs_open(filename, 0, 0);
if (fd < 0) {
panic("should not reach here");
}
Elf_Ehdr elf;
assert(fs_read(fd, &elf, sizeof(elf)) == sizeof(elf));
// 检查魔数
assert(*(uint32_t *)elf.e_ident == 0x464c457f);
// 检查ISA
assert(elf.e_machine == EXPECT_TYPE);
Elf_Phdr phdr;
for (int i = 0; i < elf.e_phnum; i++) {
uint32_t base = elf.e_phoff + i * elf.e_phentsize;
fs_lseek(fd, base, SEEK_SET);
assert(fs_read(fd, &phdr, elf.e_phentsize) == elf.e_phentsize);
// 需要装载的段
if (phdr.p_type == PT_LOAD) {
char * buf_malloc = (char *)malloc(phdr.p_filesz);
fs_lseek(fd, phdr.p_offset, SEEK_SET);
assert(fs_read(fd, buf_malloc, phdr.p_filesz) == phdr.p_filesz);
memcpy((void*)phdr.p_vaddr, buf_malloc, phdr.p_filesz);
memset((void*)phdr.p_vaddr + phdr.p_filesz, 0, phdr.p_memsz - phdr.p_filesz);
free(buf_malloc);
}
}
assert(fs_close(fd) == 0);
return elf.e_entry;
}
其实就是把ramdisk_read替换为fs_lseek和fs_read调用。
Nanos-lite直接把文件编译进二进制了, 并放到了内存指定位置.
实现完整的文件系统
记得把用户层的系统调用补上。。。(navy-apps/libs/libos/src/syscall.c)
因为用户层的系统调用默认实现是直接exit,TM找了我半天;恰巧我的strace日志是调用后才打印,所以exit时来不及打日志,什么都观察不到没有就退出了。
这说明:
- 不要随便
exit,不得不用时请在exit之前打印日志。 - 日志先行
把串口抽象成文件
WARNING:
stdin,stdout和stderr是默认打开的,所以不要在open的时候才对Finfo的read、write成员赋值。
实现gettimeofday
int main() {
struct timeval start, end;
gettimeofday(&start, NULL);
while (1) {
gettimeofday(&end, NULL);
// 超过0.5秒打印一次
if (end.tv_sec - start.tv_sec >= 0 && end.tv_usec - start.tv_usec >= 500000) {
printf("Hello world!\n");
start = end;
}
}
return 0;
}
实现NDL的时钟
修改后的timer-test如下:
int main() {
uint32_t last_tick = NDL_GetTicks();
while (1) {
uint32_t tick = NDL_GetTicks();
if (tick - last_tick >= 500) {
printf("Hello world!\n");
last_tick = tick;
}
}
return 0;
}
编译时别忘了在Makefile里加上LIBS += libndl,否则找不到NDL库
把按键输入抽象成文件
主要就是实现AM_INPUT_KEYBRD寄存器读取
size_t events_read(void *buf, size_t offset, size_t len) {
AM_INPUT_KEYBRD_T t = io_read(AM_INPUT_KEYBRD);
return snprintf((char *)buf, len, "%s %s\n",
t.keydown ? "kd" : "ku",
keyname[t.keycode]);
}
用fopen()还是open()?
用open()!上面这个需求是操作字符设备,fopen()通常是操作regular file,读取会带一个buffer(即读写一个字符不是百分百读写磁盘的)
如果你用fopen(),你会发现后面navy-apps用ISA=native根本跑不起来,因为native.cpp里的实现就不会找这些字符设备。
在NDL中获取屏幕大小
主要就是实现从AM_GPU_CONFIG寄存器读取
size_t dispinfo_read(void *buf, size_t offset, size_t len) {
AM_GPU_CONFIG_T t = io_read(AM_GPU_CONFIG);
return snprintf((char *)buf, len, "WIDTH:%d\nHEIGHT:%d\n", t.width, t.height);
}
把VGA显存抽象成文件
这个需求主要是参数比较难理解:梳理清楚系统屏幕(即frame buffer), NDL_OpenCanvas()打开的画布, 以及NDL_DrawRect()指示的绘制区域之间的位置关系。
在SDL库中,有屏幕大小、窗口、画布的概念,窗口对应的SDL_Window,画布对应SDL_Renderer,一个SDL_Window可以关联多个SDL_Renderer,但同一时间只有SDL_Renderer活跃。
回到PA
NDL_OpenCanvas(int *w, int *h)是画布的抽象,这里窗口大小等于屏幕大小。
NDL_DrawRect(uint32_t *pixels, int x, int y, int w, int h),这里的x、y是基于画布原点的坐标。
画布是一个“面向程序”的概念,所以我们系统调用的时候应该还原为屏幕位置。
fb_write
首先要知道offset的含义,才能计算坐标,offset是以字节为单位的,应该是屏幕的第n个像素,所以除以屏幕宽度,商就是y,余数就是x。
因为我们光靠offset得不到w,h, 所以只能采取逐行写入的方式(反正vga也是逐行写入的)
size_t fb_write(const void *buf, size_t offset, size_t len) {
AM_GPU_CONFIG_T t = io_read(AM_GPU_CONFIG);
int y = offset / t.width;
int x = offset - y * t.width;
io_write(AM_GPU_FBDRAW, x, y, (void*)buf, len, 1, true);
return len;
}
NDL_DrawRect
我们需要按照上面的定义计算出一个offset: offset = 屏幕宽度 * 行号 + 列号
但是要注意两点,
- 行列是相对画布来说的,所以要加上画布的原点位置。
pixels指针要加上偏移量
void NDL_DrawRect(uint32_t *pixels, int x, int y, int w, int h) {
// i is row_num counter
int fd = open("/dev/fb", 0, 0);
for (int i = 0; i < h && i + y < canvas_h; i++) {
int offset = (canvas_y + y + i) * screen_w + (canvas_x + x);
lseek(fd, offset, SEEK_SET);
w = canvas_w - x > w ? canvas_w - x : w;
write(fd, pixels + i * w, w);
}
close(fd);
}

成功绘图~就是有点慢
但是当navy-apps使用ISA=native,图片变得奇怪了。。

说明我们的实现有问题,问题在哪里呢,切到ISA=native之后,系统调用实现就不是nanos-lite了,此时我们假设系统调用实现是正确的(大腿),那就是NDL_DrawRect实现有误:
我们系统调用的时候,使用的offset、len都是字节为单位的,但是NDL_DrawRect的参数,都是以像素为单位的(4bytes),系统调用的时候,offset、len应该*4,而pixels单位和其他参数一致,所以迭代时不用修改。
修改后的代码
void NDL_DrawRect(uint32_t *pixels, int x, int y, int w, int h) {
// i is row_num counter
for (int i = 0; i < h && i + y < canvas_h; i++) {
int offset = (canvas_y + y + i) * screen_w + (canvas_x + x);
lseek(fb_fd, 4 * offset, SEEK_SET);
w = canvas_w - x > w ? canvas_w - x : w;
write(fb_fd, pixels + i * w, 4 * w);
}
}
但是新问题又来了。。ISA=native重新运行是正确了,换成riscv32-nemu又黑屏了。
记得最开始实现时绘图是正确的吗,既然NDL实现错了,说明nanos-lite实现也错了。。
事实上,__am_gpu_fbdraw的实现也是以像素为单位的,所以系统调用里又得把字节单位的变量,转为4bytes单位。
修正后的nanos-lite实现如下:
size_t fb_write(const void *buf, size_t offset, size_t len) {
AM_GPU_CONFIG_T t = io_read(AM_GPU_CONFIG);
offset = offset / 4;
int w = len / 4;
int y = offset / t.width;
int x = offset - y * t.width;
io_write(AM_GPU_FBDRAW, x, y, (void*)buf, w, 1, true);
return len;
}
WARNING: 因为
ISA=native每次打开文件返回的文件描述符是会变的(用了dup),所以推荐非regular file只打开一次,否则有奇奇怪怪的问题。
实现居中的画布
void NDL_OpenCanvas(int *w, int *h) {
// NWM_APP logic ...
if (*w == 0 && *h == 0) {
*w = screen_w;
*h = screen_h;
}
canvas_w = *w;
canvas_h = *h;
// 这里实现居中
canvas_x = (screen_w - canvas_w) / 2;
canvas_y = (screen_h - canvas_h) / 2;
assert(canvas_x + canvas_w <= screen_w);
assert(canvas_y + canvas_h <= screen_h);
}
精彩纷呈的应用程序
比较fixedpt和float
fixedpt和float类型的数据都是32位, 它们都可以表示2^32个不同的数. 但由于表示方法不一样, fixedpt和float能表示的数集是不一样的. 思考一下, 我们用fixedpt来模拟表示float, 这其中隐含着哪些取舍?
定点数的精度比浮点数低,浮点数值集中在0附近,越远离0越稀疏
神奇的fixedpt_rconst
阅读fixedpt_rconst()的代码, 从表面上看, 它带有非常明显的浮点操作, 但从编译结果来看却没有任何浮点指令. 你知道其中的原因吗?
原因就是编译器把浮点数干没了
我们预处理一下
((fixedpt)((1.2) * ((fixedpt)((fixedpt)1 << (32 - 24))) + ((1.2) >= 0 ? 0.5 : -0.5)));
可以看到数据类型转成了fixedpt, 而fixedpt定义是typedef int32_t fixedpt;
+0.5,-0.5则是很常见的round操作,即实现四舍五入,加上这个偏移量,可以得到一个较接近的浮点数
要注意的是,正如这个宏的名字中的const,这种转换只适合编译期的转换。如果是运行时转换,你需要实现下面的需求。
实现更多的fixedptc API
为了让大家更好地理解定点数的表示, 我们在
fixedptc.h中去掉了一些API的实现, 你需要实现它们. 关于fixedpt_floor()和fixedpt_ceil(), 你需要严格按照man中floor()和ceil()的语义来实现它们, 否则在程序中用fixedpt_floor()代替floor()之后行为会产生差异, 在类似仙剑奇侠传这种规模较大的程序中, 这种差异导致的现象是非常难以理解的. 因此你也最好自己编写一些测试用例来测试你的实现.
floor()向下取整,ceil()向上取整
需要实现的都在这里
/* Divides a fixedpt number with an integer, returns the result. */
static inline fixedpt fixedpt_divi(fixedpt A, int B) {
return A / B;
}
/* Multiplies two fixedpt numbers, returns the result. */
static inline fixedpt fixedpt_mul(fixedpt A, fixedpt B) {
// 多了一个2^8, 除掉他
return A * B FIXEDPT_FBITS;
}
/* Divides two fixedpt numbers, returns the result. */
static inline fixedpt fixedpt_div(fixedpt A, fixedpt B) {
// 除数变成(B / FIXEDPT_ONE),就和 fixedpt_divi 一致了
return A / (B >> FIXEDPT_FBITS);
}
static inline fixedpt fixedpt_abs(fixedpt A) {
// 如果<0, 求相反数
return A < 0 ? -A : A;
}
static inline fixedpt fixedpt_floor(fixedpt A) {
// 没有小数,直接返回, 这个条件就包含了+0/-0了
if (fixedpt_fracpart(A) == 0) return A;
// 有小数且正数,直接取整数部分
if (A > 0) return A & (~FIXEDPT_FMASK);
// 有小数且负数,先取相反数为正数+1,再转回去
else return -(((-A) & (~FIXEDPT_FMASK)) + FIXEDPT_ONE);
}
static inline fixedpt fixedpt_ceil(fixedpt A) {
// 没有小数,直接返回, 这个条件就包含了+0/-0了
if (fixedpt_fracpart(A) == 0) return A;
// 有小数且正数,取整数部分+1
if (A > 0) return (A & (~FIXEDPT_FMASK)) + FIXEDPT_ONE;
// 有小数且负数,先取相反数,保留整数部分,取相反数
else return -((-A & ~FIXEDPT_FMASK));
}
记得对负数求二补数(即取相反数),再进行计算。
如何将浮点变量转换成fixedpt类型?
假设有一个
void *p的指针变量, 它指向了一个32位变量, 这个变量的本质是float类型, 它的真值落在fixedpt类型可表示的范围中. 如果我们定义一个新的函数fixedpt fixedpt_fromfloat(void *p), 如何在不引入浮点指令的情况下实现它?
这个就要去解析float的结构了,浮点数标准大多数菜用IEEE754(TODO)
神奇的LD_PRELOAD
LD_PRELOAD是个环境变量,只作用于动态链接的库,用于指示加载器在装在C语言运行库之前载入LD_PRELOAD指定的共享链接库,达到inject同名函数的目的。
在navy-apps/scripts/native.mk可以看到,
run: app env
@LD_PRELOAD=$(NAVY_HOME)/libs/libos/build/native.so $(APP) $(mainargs)
通过劫持fopen、open等项目用到的库函数,我们可以把path重定向到真正的磁盘位置,再用原始的glibc函数去调用。
Wine, WSL和运行时环境兼容
仍旧是proxy思想
Navy中的应用程序
NSlider (NJU Slider)
前置准备参考navy-apps/apps/nslider/README.md,运行之后,卧槽黑屏?之前bmp-test明明是好的。
If ‘x’, ‘y’, ‘w’ and ‘h’ are all 0, SDL_UpdateRect will update the entire screen.
可以看到navy-apps/apps/nslider/src/main.cpp里的SDL_UpdateRect(slide, 0, 0, 0, 0);参数全是0,
需要在NDL_DrawRect实现里加上
if (x == 0 && y == 0 && w == 0 && h == 0) {
w = screen_w; // w 直接赋值屏幕宽度
h = screen_h; // h 直接赋值屏幕高度
}
WARNING: 实现
SDL_PollEvent时记得在NONE的时候要返回SDL_KEYUP,否则,由于栈上SDL_Event重复使用,按键会一致处于SDL_KEYDOWN状态。
现象就是:按一次翻页,会直接翻到第一页或最后一页。
MENU (开机菜单)
RTFM即可,注意SDL_Surface的pixels是以字节为单位的,需要转成uint32_t *再操作指针。
NTerm
实现内建的echo命令
下面有贴代码
Flappy Bird

riscv32-nemu成功运行,但是几乎不能玩,在ARCH=native可以成功运行。
“计算机是个抽象层"的应用: 移植和测试
移植测试的过程应该在如下环境依次测试
- Linux native: 直接跑程序,保证客户程序代码是正确的,需要单独一个
Makefile - Navy native: 使用Navy库,测试Navy的
libdnl/libam/libminiSDL/libfixedptc的实现(系统调用是host实现) - AM native: 即
ARCH=native,用Nanos-lite引导程序,测试Nanos-lite/libos的系统调用实现(也可以测klib实现) - NEMU: 用NEMU代替硬件,解释执行全部指令,测试
AM的实现以及TRM的实现。
PAL
ISA=native一直报这个core,
#0 0x00007ffff78a179f in unlink_chunk (p=p@entry=0x555555f56d50, av=0x7ffff7a19c80 <main_arena>)
at ./malloc/malloc.c:1628
#1 0x00007ffff78a46ab in _int_malloc (av=av@entry=0x7ffff7a19c80 <main_arena>, bytes=bytes@entry=40)
at ./malloc/malloc.c:4307
#2 0x00007ffff78a51b9 in __GI___libc_malloc (bytes=40) at ./malloc/malloc.c:3329
#3 0x00005555555a1c78 in SDL_CreateRGBSurface (flags=64, width=320, height=200, depth=8, Rmask=0, Gmask=0, Bmask=0,
Amask=2805803502) at /home/ohuang/GitProjects/ics2022/navy-apps/libs/libminiSDL/src/video.c:103
#4 0x0000555555593366 in VIDEO_CreateCompatibleSizedSurface (pSource=0x555555f0e940, pSize=0x0)
at /home/ohuang/GitProjects/ics2022/navy-apps/apps/pal/repo/src/device/video.c:757
#5 0x00005555555932c9 in VIDEO_CreateCompatibleSurface (pSource=0x555555f0e940)
at /home/ohuang/GitProjects/ics2022/navy-apps/apps/pal/repo/src/device/video.c:730
#6 0x00005555555863eb in PAL_SplashScreen ()
at /home/ohuang/GitProjects/ics2022/navy-apps/apps/pal/repo/src/main.c:220
#7 0x0000555555586d11 in main (argc=1, argv=0x7fffffffdd38)
at /home/ohuang/GitProjects/ics2022/navy-apps/apps/pal/repo/src/main.c:472
按照讲义,pal使用的是8位像素,我在想有可能是8位像素操作成了32位像素导致的内存越界,进而造成的下一次malloc失败,不管了,死马当活马医
开了
-fsanitize=address也没任何提示,你有排查思路吗 =。=
调色板
需要更新SDL_BlitSurface、SDL_FillRect、SDL_UpdateRect,具体的做法是判断SDL_Surface参数的调色板s->format->palette是否为NULL,如果为NULL,和旧逻辑一样,如果不为NULL,需要在调用NDL_DrawRect前,按照pixels索引和调色板生成一个新的32位pixels数组。
typedef union {
struct {
uint8_t r, g, b, a;
};
uint32_t val;
} SDL_Color;
SDL_Color color = s->format->palette->colors[pixels[??]];
因为SDL_Color的结构体成员是r, g, b, a排序的,而我们要的32位pixels的格式为AARRGGBB(项目搜索SDL_PIXELFORMAT_ARGB8888). 所以SDL_Color需要做下转换. 如何确定我们需要的
pixels[i] = color.a << 24 | color.r << 16 | color.g << 8 | color.b;
修复之后,正常启动!
但是,按键没反应。
SDL_GetKeyState
看PAL里的实现: 监听键盘事件是调用SDL_PollEvent直到有事件过来,然后立即调用SDL_GetKeyState的到键盘状态。
根据这个需求,我们应该需要在维护一个键盘状态数组key_state,在SDL_PollEvent有事件的时候顺便更新key_state。
实现后,成功进入游戏!
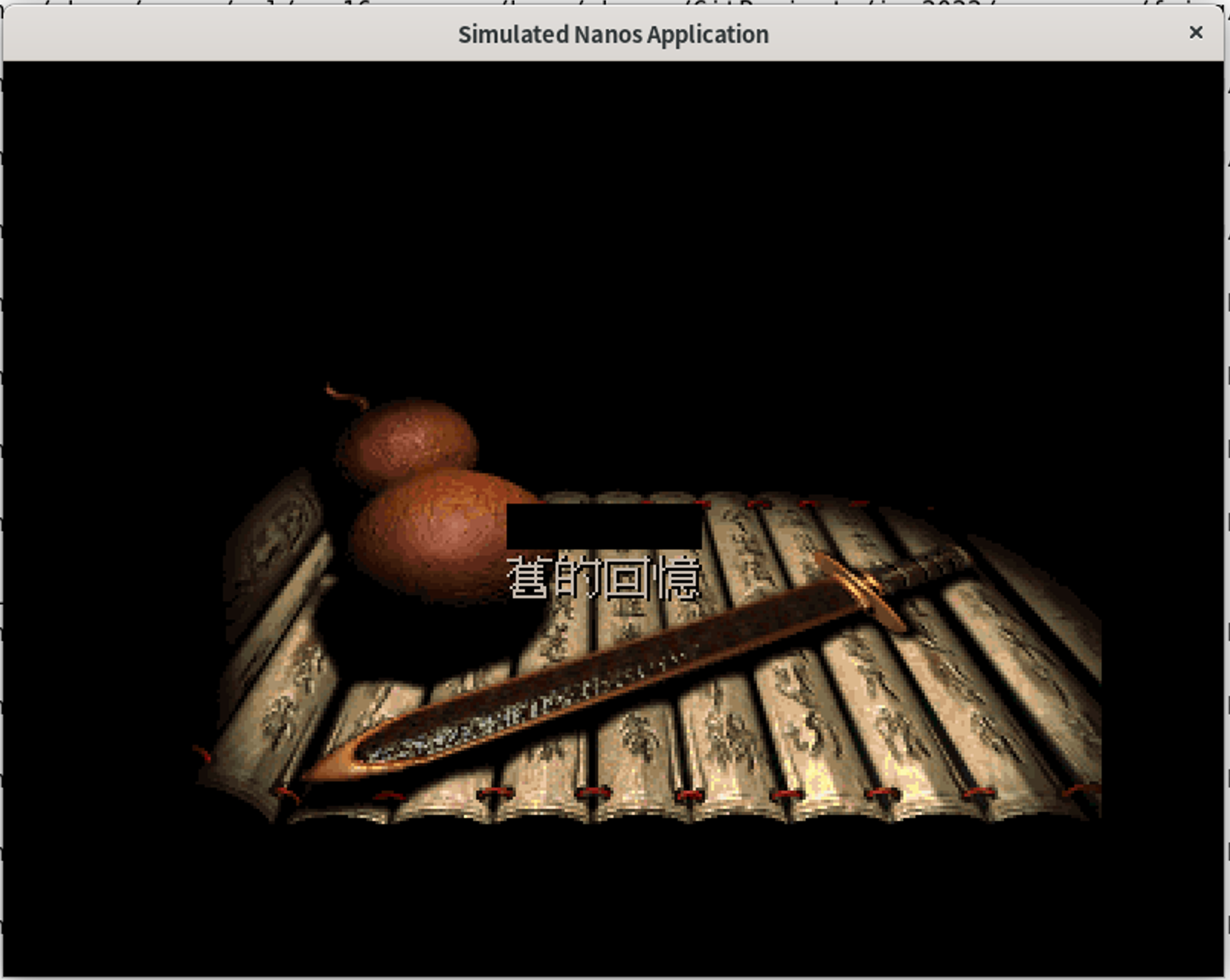
但是为什么有黑块?黑色对应的RGB为0,所以出现黑块很可能是某些拷贝行为从画布外(超出了w,h的范围)拷贝了0的color。
PAL的渲染过程是先调用SDL_BlitSurface,再调用SDL_UpdateRect,先看SDL_UpdateRect。。
gdb一波,很幸运,很快就发现问题,SDL_UpdateRect执行到函数最后一行,32位pixels数组的值都是0,说明拷贝的源位置不符合预期(pixels下标越界了)
修复再运行,这是ARCH=native,比较流畅
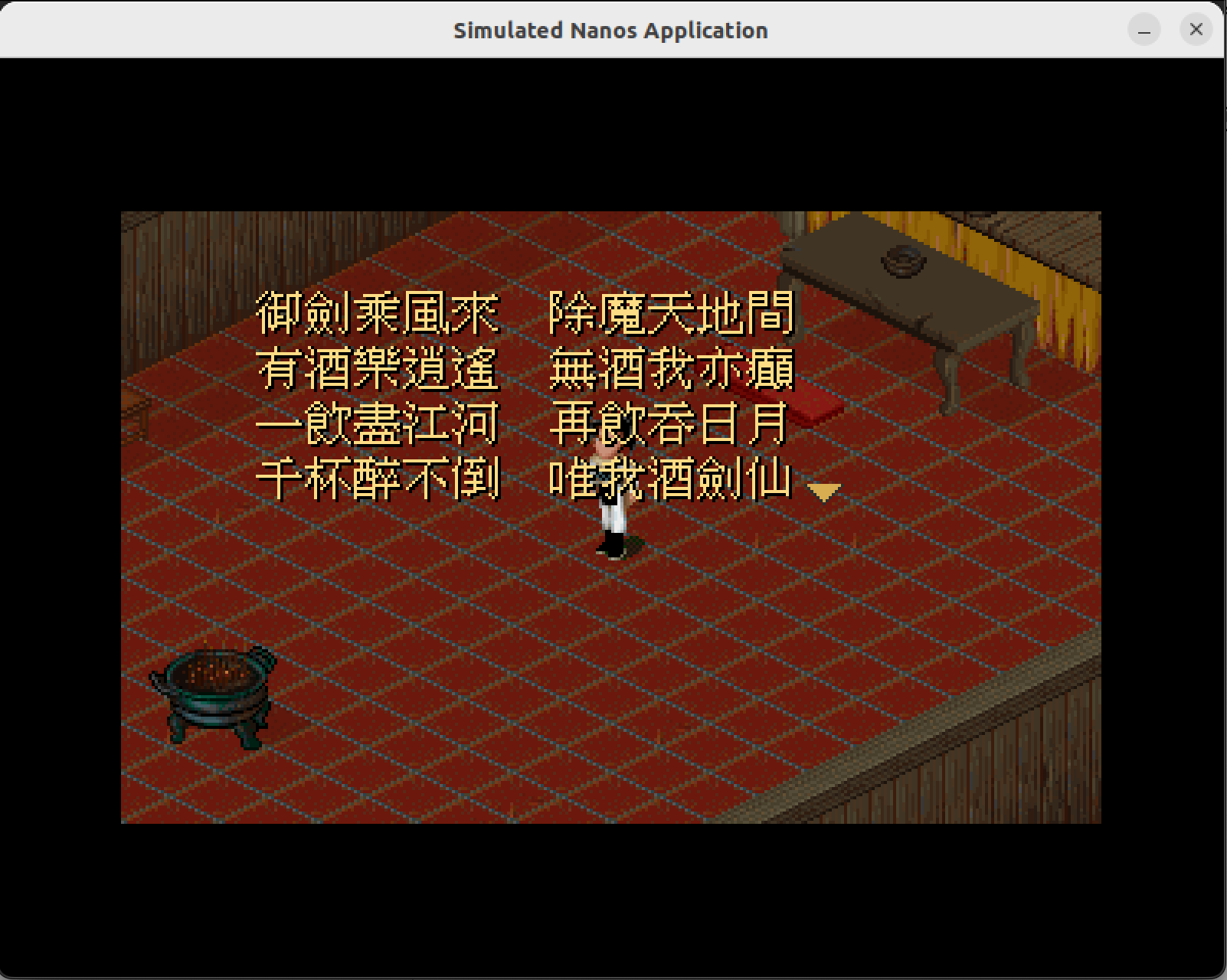
有些场景不能很好地运行,日后在说。
这是ARCH=riscv32-nemu,因为每绘制一行就得同步屏幕,实在是太慢了(又不是不能用)

仙剑奇侠传的框架是如何工作的?
TODO
仙剑奇侠传的脚本引擎
TODO
不再神秘的秘技
TODO
am-kernels
假设我们用ARCH=riscv32-nemu运行,我们最终调用链路是:
guest -> libam -> Navy -> Nanos-lite -> AM
兜兜转转还是调用了AM的API,不过stdlib的实现就不是自己那套挫逼实现了。(Navy非native都是默认依赖libc,libos的)
实现Navy上的AM
我们不要一次性实现所有API/寄存器,只需要在API/寄存器未实现时panic就好
// navy-apps/libs/libam/src/ioe.c
#include <am.h>
#include <klib-macros.h>
typedef void (*handler_t)(void *buf);
static void *lut[128] = {
// [AM_TIMER_CONFIG] = __am_timer_config,
};
static void fail(void *buf) { panic("access nonexist register"); }
bool ioe_init() {
for (int i = 0; i < LENGTH(lut); i++)
if (!lut[i]) lut[i] = fail;
return true;
}
void ioe_read (int reg, void *buf) { ((handler_t)lut[reg])(buf); }
void ioe_write(int reg, void *buf) { ((handler_t)lut[reg])(buf); }
WARNING:
navy-apps/libs/libam/src/trm.cpp先实现,否则panic没有日志,也无法退出。
实现过程基本就是调用NDL库
WARNING: 实现
__am_input_keybrd时,NDL_PollEvent应该优先判断返回码来决定有没有事件,事实上我们写业务也不能绕过返回码来写代码。
在Navy中运行microbench
TODO
FCEUX
运行FCEUX
ISA=native运行: fceux-am/Makefile注释掉-D__NO_FILE_SYSTEM__,然后执行在Navy-apps里make ISA=native mainargs=mario.nes
TODO: ARCH=native运行
TODO: ARCH=riscv32-nemu运行
如何在Navy上运行Nanos-lite?
我们梳理一下调用链路,如果在Navy上运行Nanos-lite, 调用链路是这样的:
客户程序 -> Navy -> Nanos-lite -> Navy -> `?`
?表示下游,Navy作为一个抽象层,客户程序只要调用Navy的API,而API后面的实现无需感知。
要在Nanos-lite上运行,客户程序在Navy里编译时不能是ISA=native,也就是必须用libos的syscall.c实现,此时产生的异常会被am_native的sig_hanlder或者$ISA-nemu捕获,最终调用到user_handler,执行完毕后恢复上下文回到原来的PC。
这么一梳理好像不需要任何额外支持,以后试试。
事实上,系统调用不属于任何信号,但是AM还是通过sig_hanlder实现了ARCH=am_native系统调用的重定向,libos里的关于am_native的系统调用是call了一个非法地址,然后通过SIGSEGV信号捕获系统调用。同时也没有trap.S代码,trap是在abstract-machine/am/src/native/cte.c里用setup_stack函数实现的。
#if defined(__ISA_X86__)
...
#elif defined(__ISA_AM_NATIVE__)
# define ARGS_ARRAY ("call *0x100000", "rdi", "rsi", "rdx", "rcx", "rax")
基础设施
自由开关difftest
nemu/tools/spike-diff/difftest.cc里可以看到
struct diff_context_t {
word_t gpr[32];
word_t pc;
};
这里只有32个通用寄存器和一个PC,所以给机器寄存器是比较麻烦的。
具体实现: 设置一个全局变量is_in_difftest_mode,然后实现下面两个函数:
difftest_detach: 把is_in_difftest_mode置为false,然后让difftest_step(),difftest_skip_dut()和difftest_skip_ref()直接返回。difftest_attach: 因为每个ISA的机器寄存器不一样,需要在每个ISA实现isa_difftest_attach,具体做法是:- 拷贝通用寄存器和PC
- 拷贝内存
[0x100000, PMEM_SIZE), - 写一段指令给机器寄存器赋值,然后把这段代码送入
REF,执行这段代码,就可以对齐机器寄存器(好的我不会,用llvm库应该可以实现)
快照
在这个实验里,具体要保存的内容:
- Context
- PC
- 堆栈
- 打开的文件状态
(日后再说。
展示你的批处理系统
可以运行其它程序的开机菜单
调用号为SYS_execve,没什么特别要注意的
为NTerm中的內建Shell添加环境变量的支持
修改SYS_execve,如果path不是以/开头,要从envp参数取得PATH,获得value并和path拼接,再调用naive_load(这里假设PATH路径只有一个,所以不用:分割)。
接下来实现Nterm的sh_handle_cmd:
#define CMD_ECHO "echo"
static void sh_handle_cmd(const char *cmd) {
assert(cmd);
char *cpy = (char *)malloc(strlen(cmd) + 1);
strcpy(cpy, cmd);
// remove last return
size_t len = strlen(cpy);
if (len > 0 && cpy[len-1] == '\n') {
cpy[len-1] = '\0';
}
// extract the first token as the command
char *cmd_ = strtok(cpy, " ");
if (cmd_ == NULL) {
free(cpy);
return;
}
// lite echo
if (strncmp(cmd_, CMD_ECHO, strlen(CMD_ECHO)) == 0) {
sh_printf("%s\n", cmd_ + strlen(cmd_) + 1);
free(cpy);
return;
}
// execve
char *argv[20];
char *arg;
int argc = 0;
while ((arg = strtok(NULL, " "))) {
argv[argc++] = arg;
}
argv[argc] = NULL;
execve(cmd_, argv, environ);
perror("execve");
free(cpy);
}
之后就可以在Nterm里运行
终极拷问
当你在终端键入./hello运行Hello World程序的时候, 计算机究竟做了些什么?
这个问题有点像"从浏览器地址栏输入url到请求返回发生了什么"这个经典问题。
添加开机音乐
TODO
必答题 - 理解计算机系统
仙剑奇侠传究竟如何运行
我们在<>里备注当前步骤的运行环境,列出主要的流程。
读取mgo.mkf
mkf文件其实有一个索引表,通过索引表和uiChunkNum,就能从mgo.mkf读出像素文件
PAL_MKFReadChunk<guest> -> seek<libos> -> syscall<libos>
| -> trap<NEMU>
| -> SYS_read<Nanos-lite>
| -> memcpy<AM>
|
|-----> read<libos> -> syscall<libos>
-> trap<NEMU>
-> SYS_lseek<Nanos-lite>
读取键盘事件
PAL_ProcessEvent<guest> -> SDL_PollEvent<guest> -> read<libos> -> syscall<libos>
-> trap<NEMU>
-> SYS_read<Nanos-lite>
-> io_read(AM_INPUT_KEYBRD)<AM>
计时
SDL_GetTicks<guest> -> gettimeofday<libos> -> syscall<libos>
-> trap<NEMU>
-> SYS_gettimeofday<Nanos-lite>
-> io_read(AM_TIMER_UPTIME)<AM>
更新屏幕
VIDEO_UpdateScreen<guest> -> SDL_UpdateRect<guest> -> write<libos> -> syscall<libos>
-> trap<NEMU>
-> SYS_write<Nanos-lite>
-> io_write(AM_GPU_FBDRAW)<AM>
游戏实现
- 渐变: 每帧更换一个更亮的调色板
- 仙鹤: 预生成仙鹤坐标,每帧更换坐标
其他
注意ramdisk镜像的大小, 不要放入过多过大的文件,如果遇到奇怪的错误,不妨去files.h检查下所有文件的总大小(不要超过48m)
结尾
PA3结束,准备进入PA4