终于结束了😊
PCB在linux里就是task_struct, PA的PCB里的匿名结构体就是thread_info
多道程序
为什么需要使用不同的栈空间
如果是批处理系统就可以用相同的栈空间. 但是我们加入了上下文切换, 如果共享栈空间,进程切换的时候就会互相破坏. 当然, 这里的栈空间是指物理空间。
为什么不叫"内核进程"?
因为在内核里,进程和线程的结构体都是task_struct,他们都是clone()调用生成的. 至于 “线程更加轻量级” 体现在切换上是由线程库切换,“线程没有独立的资源” 体现在和进程共享内存.
实现上下文切换
kcontext
Context *kcontext(Area kstack, void (*entry)(void *), void *arg) {
Context *c = (Context *)kstack.end - 1; // end是栈底,所以-1使sp下移一个Context的大小
c->mepc = (uintptr_t)entry;
return c;
}
context_kload
这个函数签名没有给出,不过从题目大概可以推出这个函数的签名,实现如下
void context_kload(PCB *pcb, void (*entry)(void *), void *arg);
因为Area的注释如下
// Memory area for [@start, @end)
typedef struct {
void *start, *end;
} Area;
可以看出start是低地址,end是高地址(栈底)
void context_kload(PCB *pcb, void (*entry)(void *), void *arg) {
Area area;
area.start = pcb->stack;
area.end = pcb->stack + STACK_SIZE;
pcb->cp = kcontext(area, entry, arg);
}
__am_asm_trap
diff --git a/abstract-machine/am/src/riscv/nemu/trap.S b/abstract-machine/am/src/riscv/nemu/trap.S
index fdc3d15..aafe11b 100644
--- a/abstract-machine/am/src/riscv/nemu/trap.S
+++ b/abstract-machine/am/src/riscv/nemu/trap.S
@@ -49,6 +49,7 @@ __am_asm_trap:
mv a0, sp
jal __am_irq_handle
+ mv sp, a0
LOAD t1, OFFSET_STATUS(sp)
LOAD t2, OFFSET_EPC(sp)
把sp指针指向新的上下文,然后__am_asm_trap就会根据新的上下文恢复现场啦(这里一度写成mv sp, radebug了半天🥹)
实现上下文切换(2)
diff --git a/abstract-machine/am/src/riscv/nemu/cte.c b/abstract-machine/am/src/riscv/nemu/cte.c
index 2425706..3fcf877 100644
--- a/abstract-machine/am/src/riscv/nemu/cte.c
+++ b/abstract-machine/am/src/riscv/nemu/cte.c
@@ -39,6 +39,7 @@ bool cte_init(Context*(*handler)(Event, Context*)) {
Context *kcontext(Area kstack, void (*entry)(void *), void *arg) {
Context *c = (Context *)kstack.end - 1;
c->mepc = (uintptr_t)entry - 4;
+ c->GPR2 = (uintptr_t)arg;
return c;
}
riscv的调用约定是用a0-a7传递参数,我们把arg放到a0寄存器即可.
再增加一个线程,可以看到两个线程交替输出.

实现多道程序系统
ucontext()
Context *ucontext(AddrSpace *as, Area kstack, void *entry) {
Context *c = (Context *)kstack.end - 1;
c->mepc = (uintptr_t)entry;
return c;
}
context_uload
void context_uload(PCB *pcb, const char *filename) {
AddrSpace addr;
uintptr_t entry = loader(pcb, filename);
pcb->cp = ucontext(&addr, heap, (void*)entry);
pcb->cp->GPRx = (uintptr_t) heap.end;
}
_start
navy-apps/libs/libos/src/crt0/start/riscv32.S插入如下:
mv sp, a0
navy-apps/libs/libos/src/crt0/start/am_native.S插入如下:
movq %rax, %rsp
思考一下, 如何验证仙剑奇侠传确实在使用用户栈而不是内核栈?
在PALmain函数开始加个栈变量i并打印其地址(riscv32-nemu),输出:
The address of i is 0x87ffffcc
这个地址是在用户栈范围内的.
效果图
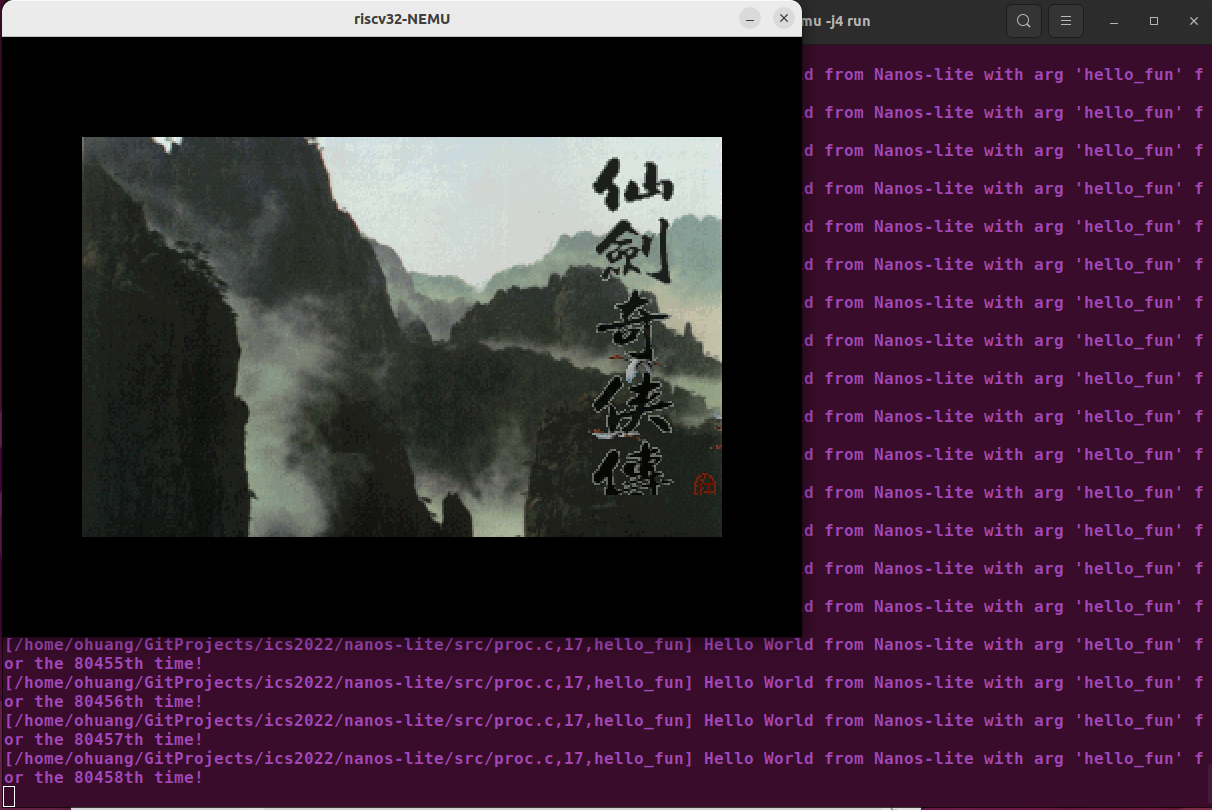 可以看到内核线程在打印,同时用户进程在渲染
可以看到内核线程在打印,同时用户进程在渲染
一山不能藏二虎?
因为两个用户进程的用户栈物理空间重叠,崩溃啦.
给用户进程传递参数
这一个需求需要根据heap.end作为sp来进行参数压栈,没什么难度,但是要求对C语言指针的理解到胃😊
具体实现是:
- 将参数、环境变量PUSH到用户栈上(我用一个
\0分隔), 同时记录字符串数量strc. - 开辟
strc+2(两个NULL指针)的指针空间,依次对argv、envp赋值 - 压栈
int argc
最后在call_main里取参数,注意因为call_main的入参是uintptr_t args,所以要注意上面压栈int argc时sp增长一个uintptr_t的空间.
为什么少了一个const?
因为实际上这些参数会被拷贝到用户栈上,所以是可以修改的.这也是我们在子进程里修改环境变量不会影响到父进程的原因.
实现带参数的execve()
修改如下
context_uload(current, path, argv, envp);
switch_boot_pcb();
yield();
execve()里调用context_uload()的pcb参数应该传current,因为exec是在原来的进程修改的,所以PCB不会改变.
接着应该调用switch_boot_pcb, 如果跳过这一步, yield()将会把上下文保存到新开辟的用户栈上, 最终上下文又从yield()对应的下一个IP开始, 然后返回,程序结束,不再调度.
说白了
pcb_boot就是个接盘侠,不要的都给他.
实现NTerm的带参命令行时,发现context_uload在执行loader后会把char **argv、char **envp的值破坏,ARCH=native运行时envp的地址是0x301a390, 而native会把客户程序加载到0x3000000附近(riscv32也是会被覆盖)
怎么办呢?
因为每次exec之后的用户栈是独立的,那就把入参拷贝到用户栈就好了.
运行Busybox(2)
需求时让execvp支持遍历,这就需要我们去了解库函数的行为.
execvp会对PATH的值逐个进行尝试,我们要做的就是在SYS_execve找不到文件时报错,这个报错也很有讲究,需要返回-ENOENT即错误码ENOENT(ERROR NO ENTRY)的相反数,库函数识别到负数,会取相反数的到正确的错误码.
超越容量的界限
虚存管理中PIC的好处
- 虚拟内存管理的最核心的是页表,而PIC最核心的是GOT,两者的思想都是查表.对于动态库来说,只要加载动态库时把代码段加载到页表,然后更新
GOT把这些符号指向页表项的linear address. - 虚拟内存管理有无限多的内存,那PIC想加载到哪个位置都是可以的.
理解分页细节
i386不是一个32位的处理器吗, 为什么表项中的基地址信息只有20位, 而不是32位?
传送门 因为i386的一页为4KB(2^12), 所以只需要用到20位来表示物理地址.剩下的12位其实也是地址,只不过他们不参与页表索引,只是个值对象.
手册上提到表项(包括CR3)中的基地址都是物理地址, 物理地址是必须的吗? 能否使用虚拟地址?
不知道,我觉得不可以.
为什么不采用一级页表? 或者说采用一级页表会有什么缺点?
缺点就是浪费内存,因为页表是个数组映射,所以是连续没有有空洞的, KEY是va, VALUE是pa, 那么我们必须按顺序填满整个va, 才能用下标作为索引.
如果只用一级页表,IISA=riscv32每个进程都要用4M(2^20 entries * 4 bytes/entry)的空间来存储页表,这对内核来说是个不小的开销.要是你能把整个内存占满,那无可厚非,而问题恰恰是在于进程不会用满所有空间(尤其是在64位操作系统中)
所以采用二级页表(多级页表),可以允许空洞的存在,减少页表的体积(就像树)
我们要做的只是在一级页表找二级页表发生缺页的时候,分配一个新的物理空间,这就是计算机的按需分配~
空指针真的是"空"的吗?
空指针当然不是"空"的,一个指针也有自己的地址,只不过这个地址上的值是0x0这个特殊值.
对空指针进行解引用的时候,会根据指针的值0x0进行访存,此时操作系统就会给出段错误.
指针本质就是一个数值!
mips32的TLB管理是否更简单?
不觉得简单,好复杂,这种底层逻辑还是硬件做比较好.
在分页机制上运行Nanos-lite
SATP寄存器的结构
 Sv32的va、pa、PTE结构
Sv32的va、pa、PTE结构

这里PTE的PPN只有22位, 也就是说这些物理页只能分配在4M * PAGESIZE的地址空间里,如果需要更大的空间,就得用到三级页表甚至四级页表.
isa_mmu_check
#define isa_mmu_check(vaddr, len, type) BITS(cpu.stap, 31, 31) ? MMU_TRANSLATE : MMU_DIRECT
事实上,手册上说明只有RISCV在S模式和U模式才会进入分页模式,但是PA隐藏了这个要求,让我们只关注于分页机制.
isa_mmu_translate
参考RISCV手册4.3节实现即可(Sv32: Page-Based 32-bit Virtual-Memory Systems), 注意assert异常情况
map
void map(AddrSpace *as, void *va, void *pa, int prot)函数的需求是把va恒等映射到pa, 在进入函数之前,一级页表已经申请好了,放在as指针中.
具体实现其实就是isa_mmu_translate的逆过程(这何尝不是一种convention)
实现的过程遇到了一点小麻烦: 页目录项被清空了, 而且是运行一段时间后被清空了.这时候PA1的
基础设施派上用场了.对目录项的地址打个watchpoint, 命中断点后通过addr2line工具+PC定位源码, 发现是klib的malloc也用到了heap.start, Nanos-lite和klib都保存了一个heap.start的副本,两个函数对同一个地址进行了写.怎么办呢?那就给你们划个号段 +
assert告警吧. 反正klib的malloc也用的不多,主要是Nanos-lite申请一段buf用于加载文件. 给klibmalloc加个0x30000的偏移量,超过这个值时assert停止程序.实际上应该在内核不应该用
malloc(参考《Linux内核设计与实现》). 后面有了页机制之后就不会再内核用到malloc了.
这里的as其实是内核空间kas, 也就是说我们的PAL是跑在内核空间的..
pg_alloc
记得清零! 这里面的数据可能会作为页表使用,如果不清零的话,这里面的脏数据会影响页表的工作.
对于x86和riscv32, 你无需实现TLB.
让DiffTest支持分页机制
日后再说.
在分页机制上运行用户进程
context_uload
修改点:
- 函数开头需要
protect, 目的是为了:- 生成页目录root page table, 保存其指针
- 声明用户地址空间
USER_SPACE - 拷贝内核地址空间映射
ucontext保存第一步的指针到Context里,Context的页目录指针是面向用户进程使用的,PCB的页目录指针是面行内核使用的.- 把
new_page得到的32KB与USER_SPACE的高地址32KB映射, 因为分页机制已经开启, 所以我们应该对pa直接压栈, 然后把pa转换为va, 作为用户进程的sp
回顾一下, 最开始实现的用户栈是直接用
TRM的heap物理地址, 后来由new_page管理, 再到后来由MMU管理, 先驱真伟大!
loader
编译Navy的时候记得加上VME=1把用户虚拟空间变成0x40000000,这么做的原因是: 0x80000000-0x88000000是属于内核虚拟空间,不应该和用户虚拟空间有重叠. 因为用户空间包含了内核空间的映射, 如果有重叠就变的不可维护了.
AM上的程序的物理空间从
_pmem_start符号开始, 在上面分配.text和.data之后的到一个end/_end符号, 然后从这里开始作为heap.start(按页向上取整), 使用new_page分配物理空间,最多可以分配到_pmem_start + 0x8000000.
如果运行时遇到页无效的错误, 多半是loader有问题(map和translate这两部分, 菜鸡如我也BugFree了).
我遇到的问题是: 对于一个segment, p_vaddr可能不是页对齐的, 往内存写入的时候要在pa + offset(p_vaddr)写入, 而不是pa处, 否则程序跑着跑着就会访问0x00000000或者其他预期外的地址而报错.这部分的代码一般是对指针解引用, 因为数据没有装载到正确地址上, 所以指针就指向一个非预期的地址了.
题外话, 把ELF加载到页的过程, 有点像拿一个ID列表批量查询数据的过程, 都是分隔入参的过程.
让DiffTest支持分页机制(2)
怎么又有.
内核映射的作用
在我的机器上是: 访问0x80002bf8失败, 原因是页目录项无效.因为这个地址是在系统启动的时候事先映射好的, 如果用户进程没有拷贝这个映射, 就无法访问这个虚拟地址.
这个地址对应的内核代码, 说明内存里内核代码只有一份, 即所有进程都共享一份内核代码.
在分页机制上运行仙剑奇侠传
这个需求是实现mm_brk.首先明确一个前提, 每个进程都能看到自己的一份program break, 所以我们在PCB里记录max_brk(max program break), 如果SYS_brk调用超过了max_brk, 则给这部分超过的分配新页.
注意: Navy的
_end和Nanos-lite的_heap_start并不挨着, 他们的ELF是不同的链接过程.
native的VME实现
可以在用户栈里面创建用户进程上下文吗?
不可以.初始化上下文的时候进程的虚拟空间还未建立, 找不到用户栈.
支持虚存管理的多道程序
在用户线程进行yield的时候, 使用的栈是用户栈的, 此时如果调用__am_switch切换到内核地址空间, 在函数调用返回后因为需要暂时回到用户栈, 这时程序就会因为地址非法挂掉.
解决办法是: 恢复内核上下文的时候不要切换地址空间, 这里是通过判断Context.pdir指针是否为NULL实现的, 相应的从内核线程中断, 保存Context的时候不要保存地址空间, 而是赋值为NULL.
之前的问题是用户态用了内核栈, 现在反过来了.因为我们内核态用到了用户栈.
并发执行多个用户进程
这个问题不是和上面的一样?
P.S. 这一小节的确很难.主要是一次实现这么多需求(虚存映射、地址翻译、ELF加载虚存、brk等), 一个地方出错就很难排查, 又不知道在哪里assert.
来自外部的声音
灾难性的后果(这个问题有点难度)
上下文被覆盖, 被中断进程回不到原来的PC, 去到错误的地址, 整个系统崩溃. (反正问就是不行)
如何支持嵌套中断
嵌套中断一般是为了满足更高优先级的中断.
实现抢占多任务
没什么注意的, 就是讲义没有把isa_query_intr的条件写出来, 条件是: ”MIE(Machine Interrupt Enable)开启“且“cpu中断引脚高电平“时, 接收中断.
word_t isa_query_intr() {
if (((cpu.mstatus >> MIE_OFFSET) & 0x1) == 1 && cpu.INTR) {
cpu.INTR = false;
return IRQ_TIMER;
}
return INTR_EMPTY;
}
中断和用户进程初始化
这里的栈指针指用户栈指针, 到目前为止, 用户进程的中断上下文是放在用户栈的, 如果栈指针没有设置就处理中断, 那就会找到错误的位置存放上下文, 可能会破坏栈上的数据.
但是一般中断都是用内核栈, 甚至x86有中断栈, 他们的栈底都是不依赖于用户栈sp的, 所以在设置栈指针之前就到来了中断, 系统是可以正常处理中断的. 稍后我们会修改实现.
优先级调度
可以在PCB加个计数器, 这个需求就跳过了.
用户态和栈指针
可以通过栈指针在判断用户态和内核态, 可以在项目里搜到这个代码
int trap_from_user = __am_in_userspace(rip);
这段代码通过IP判断从哪里陷入
系统的复杂性
之前多个用户进程跑不起来的原因, 就是进入CTE(trap)的时候, 在A的用户栈上进行页切换, 导致ret失败.
因此我们不想引用用户栈, 则需要实现如下功能:
- 如果是从用户态进入CTE, 则在CTE保存上下文之前, 先切换到内核栈, 然后再保存上下文
- 如果将来返回到用户态, 则在CTE从内核栈恢复上下文之后, 则先切换到用户栈, 然后再返回
用户态和栈指针?
我们可以通过栈指针的值来判断当前位于用户态还是内核态, 因为内核地址和用户地址是分开的.
基本功能
剖析几个关键字: 从用户态、切换到内核栈、返回到用户态、切换到用户栈
提出了四个状态:
- 如何识别进入CTE之前处于用户态还是内核态? - pp (Previous Privilege)
- CTE的代码如何知道内核栈在什么位置? - ksp (Kernel Stack Pointer)
- 如何知道将要返回的是用户态还是内核态? - np (Next Privilege)
- CTE的代码如何知道用户栈在什么位置? - usp (User Stack Pointer)
系统的复杂性(2)
np、usp被__am_irq_handle使用后会变化(上下文切换)pp、ksp被__am_irq_handle使用后被赋值
因此在np、usp会变的情况下, 为了防止旧值丢失, 需要把他们存入Context保存起来.
而pp、ksp值在被__am_irq_handle使用后会被覆盖, 所以在__am_irq_handle前可以被随意赋值. 这两个状态类似caller saved registers, 无论中间更新多少次, 只要最后能恢复为正确的值即可. (或者说像DP问题的状态压缩)
系统的复杂性(3)
问题在于pp值在没有改变. 假如pp == USER, 那么无论嵌套CTE多少次, __am_irq_handle看到的pp还是USER, 而我们的预期是从第一次嵌套开始pp就是KERNEL了.
解决办法是第一次进入CTE就把pp改为KERNEL.
判断重入的常用做法就是写标志位.
一些优化
为什么要优化呢, 这里的优化就是复用寄存器。因为寄存器是宝贵资源, 能不引入新的寄存器就不引入.
临时寄存器的方案
通过引入mscratch寄存器可以减少软件工作量. riscv设计美学就是通过增加硬件工作量, 减少软件工作量.
用GPR做CTE临时寄存器还得和软件约定好他们是caller saved registers.
既然选择riscv32肯定要说riscv的好啊
实现内核栈和用户栈之间的切换
现在才发现保存/恢复上下文的寄存器漏掉了零寄存器和sp
// abstract-machine/am/src/riscv/nemu/trap.S
#define REGS(f) \
f( 1) f( 3) f( 4) f( 5) f( 6) f( 7) f( 8) f( 9) \
...
零寄存器就不用说了, 就说为什么没有sp. 原来的设计中, Context是保存在同一个栈的, 所以只要找到了Context指针, 就是找到了sp. 现在加入了栈切换, 为了从内核栈恢复中断时能找到用户栈的sp, 所以要额外保存sp: STORE [REG], OFFSET_SP(sp), 随便找个临时寄存器存下
riscv架构中, mscratch寄存器是一个系统软件用的临时寄存器, 一般被用于临时存放ksp, 那么多个进程有多个内核栈, 一个CPU只有一个mscratch够吗? 其实是够的. 这个用状态机的视角去论证即可, 然后你就会发现mscratch只会有两个取值, 第一种是kstack.end, 第二种是0. 当进入__am_asm_trap时, 如果ksp != 0, 那么这个进程必定是刚从np = USER状态恢复而来, mscratch也必定刚被恢复为内核栈底, 所以一个CPUmscratch只需要一个, 他只要用于暂存内核栈底即可.
trap.S
主要就是改这里
#define concat_temp(x, y) x ## y
#define concat(x, y) concat_temp(x, y)
#define MAP(c, f) c(f)
#if __riscv_xlen == 32
#define LOAD lw
#define STORE sw
#define XLEN 4
#else
#define LOAD ld
#define STORE sd
#define XLEN 8
#endif
#define USER 0
#define KERNEL 1
#define REGS(f) \
f( 1) f( 3) f( 4) f( 5) f( 6) f( 7) f( 8) f( 9) \
f(10) f(11) f(12) f(13) f(14) f(15) f(16) f(17) f(18) f(19) \
f(20) f(21) f(22) f(23) f(24) f(25) f(26) f(27) f(28) f(29) \
f(30) f(31)
#define PUSH(n) STORE concat(x, n), (n * XLEN)(sp);
#define POP(n) LOAD concat(x, n), (n * XLEN)(sp);
#define CONTEXT_SIZE ((32 + 4 + 1) * XLEN)
#define OFFSET_SP ( 2 * XLEN)
#define OFFSET_CAUSE (32 * XLEN)
#define OFFSET_STATUS (33 * XLEN)
#define OFFSET_EPC (34 * XLEN)
#define OFFSET_NP (35 * XLEN)
.align 3
.globl __am_asm_trap
.globl g_np
__am_asm_trap:
csrrw sp, mscratch, sp // swap($sp, ksp)
bnez sp, save_np_user // if (ksp != 0) sp = ksp; np is USER
csrr sp, mscratch // ksp is 0(特殊值), revert sp
save_np_kernel:
addi sp, sp, -2*XLEN // push-----------------------
STORE t0, 0(sp) // push t0
STORE t1, XLEN(sp) // push t1
lui t0, KERNEL
la t1, g_np // load g_np address
STORE t0, 0(t1) // store np to g_np
LOAD t0, 0(sp) // pop t0
LOAD t1, XLEN(sp) // pop t1
addi sp, sp, 2*XLEN // pop------------------------
j save_context
save_np_user:
addi sp, sp, -2*XLEN // push-----------------------
STORE t0, 0(sp) // push t0
STORE t1, XLEN(sp) // push t1
lui t0, USER
la t1, g_np // load g_ksp address
STORE t0, 0(t1) // store np to g_np
LOAD t0, 0(sp) // pop t0
LOAD t1, XLEN(sp) // pop t1
addi sp, sp, 2*XLEN // pop------------------------
save_context:
addi sp, sp, -CONTEXT_SIZE
MAP(REGS, PUSH)
csrr t0, mcause
csrr t1, mstatus
csrr t2, mepc
csrr t3, mscratch // t3 = sp (1)步骤把入口sp放到这里了。
STORE t0, OFFSET_CAUSE(sp)
STORE t1, OFFSET_STATUS(sp)
STORE t2, OFFSET_EPC(sp)
STORE t3, OFFSET_SP(sp) // c->sp = $sp;
la t0, g_np // load g_np address
LOAD t0, 0(t0) // g_np
STORE t0, OFFSET_NP(sp) // c->np = np
# set mstatus.MPRV to pass difftest
li a0, (1 << 17)
or t1, t1, a0
csrw mstatus, t1
mv a0, sp
jal __am_irq_handle
mv sp, a0 // The Context is always on the kernel stack.
// So $sp must be on the kernel stack.
LOAD t1, OFFSET_STATUS(sp)
LOAD t2, OFFSET_EPC(sp)
csrw mstatus, t1
csrw mepc, t2
LOAD t1, OFFSET_NP(sp)
bnez t1, restore_ctx // np is KERNEL, jump to restore_ctx
addi t2, sp, CONTEXT_SIZE // ksp = $sp + CONTEXT_SIZE when return to USER
csrw mscratch, t2 // restore ksp
restore_ctx:
MAP(REGS, POP)
// addi sp, sp, CONTEXT_SIZE // no need to exec this
LOAD sp, OFFSET_SP(sp) // $sp = c->sp; this is the trap sp
mret
主要就是加上sp的保存和还原. 因为PUSH现场之后, 所有寄存器都会被覆盖, 所以用了一个全局变量来存np(感觉不太合理, 不过讲义是这么说的)
kcontext
因为要用到Context里的sp, np, 所以我们还得给kcontext初始化sp和np
Context *kcontext(Area kstack, void (*entry)(void *), void *arg) {
...
c->np = KERNEL;
c->gpr[2] = (uintptr_t)kstack.end; // sp
return c;
}
ucontext
同kcontext, ucontext也需要初始化
Context *ucontext(AddrSpace *as, Area kstack, void *entry) {
...
c->np = USER;
c->gpr[2] = (uintptr_t)as->area.end; // sp
...
}
Nanos-lite与并发bug (建议二周目/学完操作系统课思考)
不会有并发bug. 首先目前CTE的(MIE)被关, 虽然mm_brk没有加锁, 但是可以看作一个原子的过程(不会被中断).
其次两个用户进程有独立的物理空间, 他们的buffer都是隔离的, 不会出现进程A的buffer覆写进程B的buffer.
编写不朽的传奇
TODO 来日方长
后记
到这里主线已经做完了. 通过这个PA, 最终实现了一个轻量的操作系统, 支持:
- 画面输出
- 系统时间
- 键盘事件
- 简易stdlib
- 异常/中断
- 多道程序
- 进程切换
- 进程调度
- 内核线程
- 虚拟内存
- DEBUG功能
- 内核栈/用户栈切换
- 等等等
- TODO MORE
从系统调用到硬件指令一条龙模拟。
好几次想放弃这个实验, 最后还是坚持了下来🌈受益匪浅, 感谢NJU开放这个实验. 准备再战操作系统